
Introduction to Subsets Pattern
A huge number of coding interview problems involve dealing with Permutations and Combinations of a given set of elements. This pattern describes an efficient Breadth First Search (BFS) approach to handle all these problems.
Let’s jump onto our first problem to develop an understanding of this pattern.
*Subsets (easy)
78. Subsets Design Gurus Educative.io
Problem Statement
Given a set with distinct elements, find all of its distinct subsets.
Example 1:
1 | Input: [1, 3] |
Example 2:
1 | Input: [1, 5, 3] |
Constraints:
1 <= nums.length <= 10-10 <= nums[i] <= 10- All the numbers of nums are
unique.
Solution
To generate all subsets of the given set, we can use the Breadth First Search (BFS) approach. We can start with an empty set, iterate through all numbers one-by-one, and add them to existing sets to create new subsets.
Let’s take the example-2 mentioned above to go through each step of our algorithm:
Given set: [1, 5, 3]
- Start with an empty set: [[]]
- Add the first number (1) to all the existing subsets to create new subsets: [[], [1]];
- Add the second number (5) to all the existing subsets: [[], [1], [5], [1,5]];
- Add the third number (3) to all the existing subsets: [[], [1], [5], [1,5], [3], [1,3], [5,3], [1,5,3]].
Here is the visual representation of the above steps:
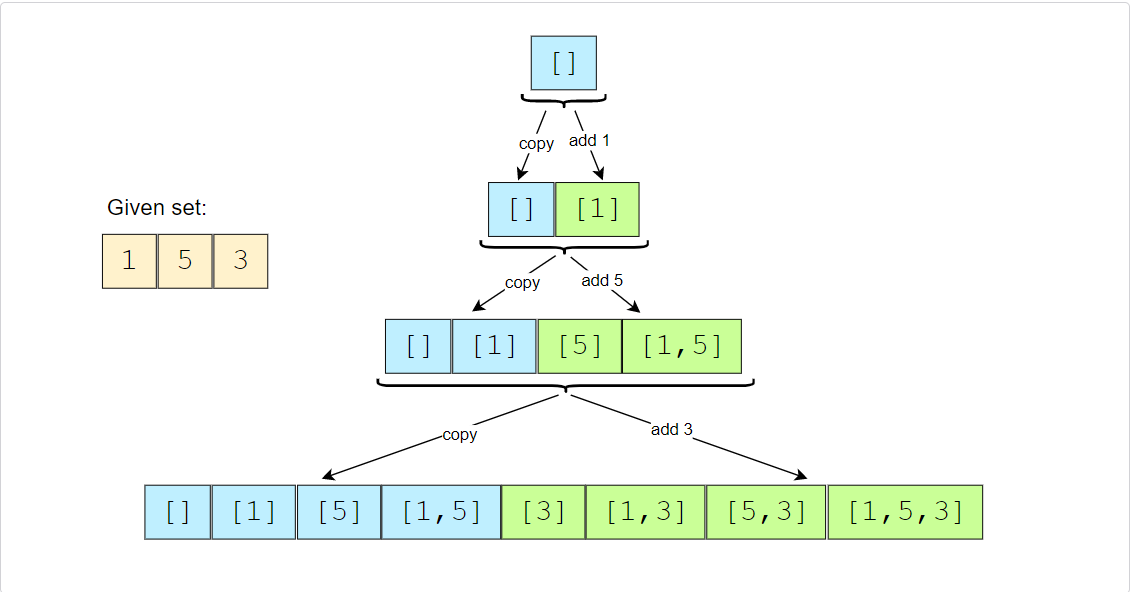
Since the input set has distinct elements, the above steps will ensure that we will not have any duplicate subsets.
Code
Here is what our algorithm will look like:
1 | class Solution: |
Time complexity
Since, in each step, the number of subsets doubles as we add each element to all the existing subsets, the time complexity of the above algorithm is O(2^N), where ‘N’ is the total number of elements in the input set. This also means that, in the end, we will have a total of O(2^N) subsets.
Space complexity
All the additional space used by our algorithm is for the output list. Since we will have a total of O(2^N) subsets, the space complexity of our algorithm is also O(2^N).
Subsets With Duplicates (easy)
90. Subsets II Design Gurus Educative.io
Problem Statement
Given a set of numbers that might contain duplicates, find all of its distinct subsets.
Example 1:l9
1 | Input: [1, 3, 3] |
Example 2:
1 | Input: [1, 5, 3, 3] |
Constraints:
1 <= nums.length <= 10-10 <= nums[i] <= 10
Solution
This problem follows the Subsets pattern and we can follow a similar Breadth First Search (BFS) approach. The only additional thing we need to do is handle duplicates. Since the given set can have duplicate numbers, if we follow the same approach discussed in Subsets, we will end up with duplicate subsets, which is not acceptable. To handle this, we will do two extra things:
- Sort all numbers of the given set. This will ensure that all duplicate numbers are next to each other.
- Follow the same BFS approach but whenever we are about to process a duplicate (i.e., when the current and the previous numbers are same), instead of adding the current number (which is a duplicate) to all the existing subsets, only add it to the subsets which were created in the previous step.
Let’s take Example-2 mentioned above to go through each step of our algorithm:
1 | Given set: [1, 5, 3, 3] |
- Start with an empty set: [[]]
- Add the first number (1) to all the existing subsets to create new subsets: [[], [1]];
- Add the second number (3) to all the existing subsets: [[], [1], [3], [1,3]].
- The next number (3) is a duplicate. If we add it to all existing subsets we will get:
1 | [[], [1], [3], [1,3], [3], [1,3], [3,3], [1,3,3]] |
To handle this instead of adding (3) to all the existing subsets, we only add it to the new subsets which were created in the previous (3rd) step:
1 | [[], [1], [3], [1,3], [3,3], [1,3,3]] |
- Finally, add the forth number (5) to all the existing subsets: [[], [1], [3], [1,3], [3,3], [1,3,3], [5], [1,5], [3,5], [1,3,5], [3,3,5], [1,3,3,5]]
Here is the visual representation of the above steps:
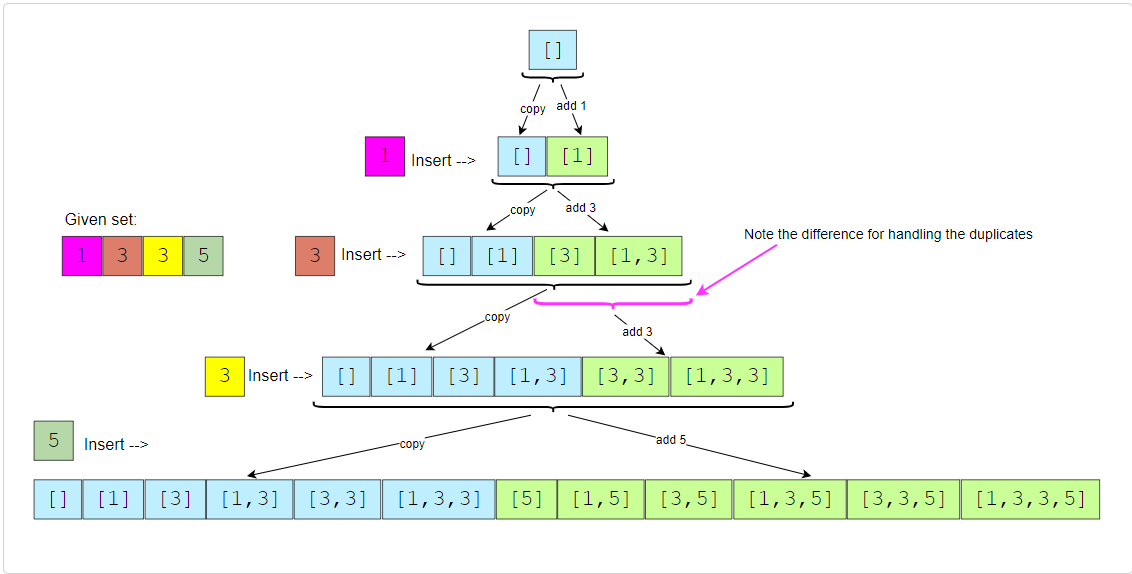
Code
Here is what our algorithm will look like:
1 | class Solution: |
Time complexity
Since, in each step, the number of subsets could double (if not duplicate) as we add each element to all the existing subsets, the time complexity of the above algorithm is O(2^N), where ‘N’ is the total number of elements in the input set. This also means that, in the end, we will have a total of O(2^N) subsets at the most.
Space complexity
All the additional space used by our algorithm is for the output list. Since at most we will have a total of O(2^N) subsets, the space complexity of our algorithm is also O(2^N).
*Permutations (medium)
Top Interview 150 | 46. Permutations Design Gurus Educative.io
Problem Statement
Given a set of distinct numbers, find all of its permutations.
Permutation is defined as the re-arranging of the elements of the set. For example, {1, 2, 3} has the following six permutations:
- {1, 2, 3}
- {1, 3, 2}
- {2, 1, 3}
- {2, 3, 1}
- {3, 1, 2}
- {3, 2, 1}
If a set has ‘n’ distinct elements it will have n!n! permutations.
Example 1:
1 | Input: [1,3,5] |
Constraints:
1 <= nums.length <= 6-10 <= nums[i] <= 10- All the numbers of
numsareunique.
Solution
This problem follows the Subsets pattern and we can follow a similar Breadth First Search (BFS) approach. However, unlike Subsets, every permutation must contain all the numbers.
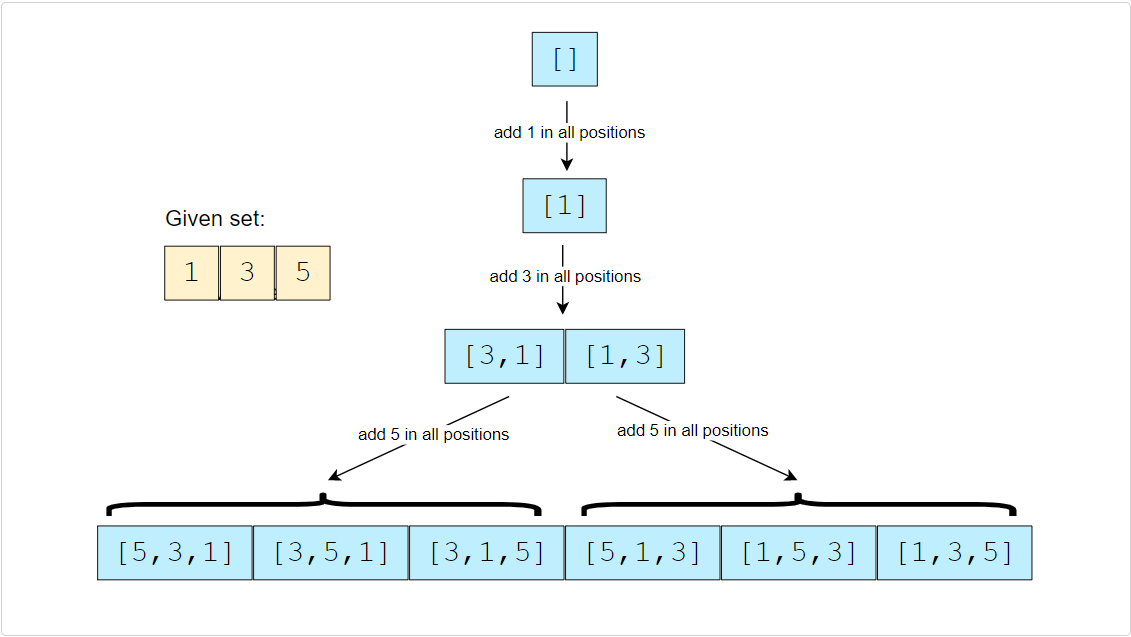
Let’s take the example-1 mentioned above to generate all the permutations. Following a BFS approach, we will consider one number at a time:
- If the given set is empty then we have only an empty permutation set: []
- Let’s add the first element (1), the permutations will be: [1]
- Let’s add the second element (3), the permutations will be: [3,1], [1,3]
- Let’s add the third element (5), the permutations will be: [5,3,1], [3,5,1], [3,1,5], [5,1,3], [1,5,3], [1,3,5]
Let’s analyze the permutations in the 3rd and 4th step. How can we generate permutations in the 4th step from the permutations of the 3rd step?
If we look closely, we will realize that when we add a new number (5), we take each permutation of the previous step and insert the new number in every position to generate the new permutations. For example, inserting ‘5’ in different positions of [3,1] will give us the following permutations:
- Inserting ‘5’ before ‘3’: [5,3,1]
- Inserting ‘5’ between ‘3’ and ‘1’: [3,5,1]
- Inserting ‘5’ after ‘1’: [3,1,5]
Here is the visual representation of this algorithm:
Code
Here is what our algorithm will look like:
1 | # 觉得的solution code有可以优化的地方,也过了leetcode |
Time complexity
We know that there are a total of N!N! permutations of a set with ‘N’ numbers. In the algorithm above, we are iterating through all of these permutations with the help of the two ‘for’ loops. In each iteration, we go through all the current permutations to insert a new number in them on line 17 (line 23 for C++ solution). To insert a number into a permutation of size ‘N’ will take O(N), which makes the overall time complexity of our algorithm O(N\N!)*.
Space complexity
All the additional space used by our algorithm is for the result list and the queue to store the intermediate permutations. If you see closely, at any time, we don’t have more than N!N! permutations between the result list and the queue. Therefore the overall space complexity to store N!N! permutations each containing NN elements will be O(N\N!)*.
Recursive Solution
Here is the recursive algorithm following a similar approach:
1 | class Solution: |
String Permutations by changing case (medium)
784. Letter Case Permutation Design Gurus Educative.io
Problem Statement
Given a string, find all of its permutations preserving the character sequence but changing case.
Example 1:
1 | Input: "ad52" |
Example 2:
1 | Input: "ab7c" |
Constraints:
1 <= str.length <= 12strconsists of lowercase English letters, uppercase English letters, and digits.
Solution
This problem follows the Subsets pattern and can be mapped to Permutations.
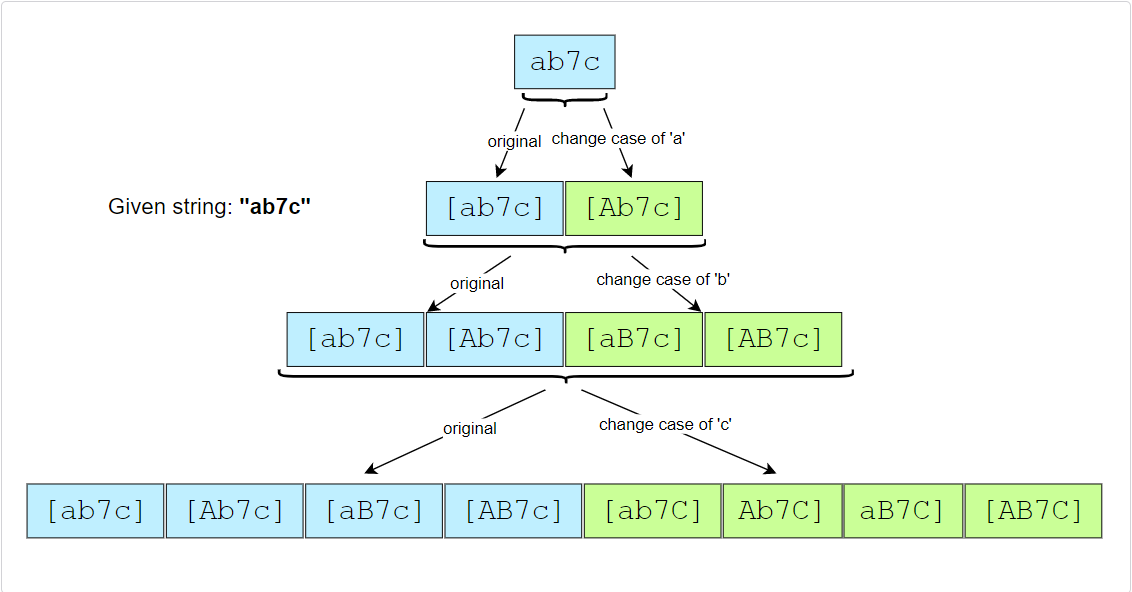
Let’s take Example-2 mentioned above to generate all the permutations. Following a BFS approach, we will consider one character at a time. Since we need to preserve the character sequence, we can start with the actual string and process each character (i.e., make it upper-case or lower-case) one by one:
- Starting with the actual string:
"ab7c" - Processing the first character (‘a’), we will get two permutations:
"ab7c", "Ab7c" - Processing the second character (‘b’), we will get four permutations:
"ab7c", "Ab7c", "aB7c", "AB7c" - Since the third character is a digit, we can skip it.
- Processing the fourth character (‘c’), we will get a total of eight permutations:
"ab7c", "Ab7c", "aB7c", "AB7c", "ab7C", "Ab7C", "aB7C", "AB7C"
Let’s analyze the permutations in the 3rd and the 5th step. How can we generate the permutations in the 5th step from the permutations in the 3rd step?
If we look closely, we will realize that in the 5th step, when we processed the new character (‘c’), we took all the permutations of the previous step (3rd) and changed the case of the letter (‘c’) in them to create four new permutations.
Here is the visual representation of this algorithm:
Code
Here is what our algorithm will look like:
1 | class Solution: |
Time complexity
Since we can have 2^N permutations at the most and while processing each permutation we convert it into a character array, the overall time complexity of the algorithm will be O(N\2^N)*.
Space complexity
All the additional space used by our algorithm is for the output list. Since we can have a total of O(2^N) permutations, the space complexity of our algorithm is O(N\2^N)*.
*Balanced Parentheses (hard)
Top Interview 150 | 22. Generate Parentheses Design Gurus Educative.io
Problem Statement
For a given number ‘N’, write a function to generate all combination of ‘N’ pairs of balanced parentheses.
Example 1:
1 | Input: N=2 |
Example 2:
1 | Input: N=3 |
Constraints:
1 <= n <= 8
Solution
This problem follows the Subsets pattern and can be mapped to Permutations. We can follow a similar BFS approach.
Let’s take Example-2 mentioned above to generate all the combinations of balanced parentheses. Following a BFS approach, we will keep adding open parentheses ( or close parentheses ). At each step we need to keep two things in mind:
- We can’t add more than ‘N’ open parenthesis.
- To keep the parentheses balanced, we can add a close parenthesis
)only when we have already added enough open parenthesis(. For this, we can keep a count of open and close parenthesis with every combination.
Following this guideline, let’s generate parentheses
for N=3:
- Start with an empty combination: “”
- At every step, let’s take all combinations of the previous step and add
(or)keeping the above-mentioned two rules in mind. - For the empty combination, we can add
(since the count of open parenthesis will be less than ‘N’. We can’t add)as we don’t have an equivalent open parenthesis, so our list of combinations will now be: “(” - For the next iteration, let’s take all combinations of the previous set. For “(” we can add another
(to it since the count of open parenthesis will be less than ‘N’. We can also add)as we do have an equivalent open parenthesis, so our list of combinations will be: “((”, “()” - In the next iteration, for the first combination “((”, we can add another
(to it as the count of open parenthesis will be less than ‘N’, we can also add)as we do have an equivalent open parenthesis. This gives us two new combinations: “(((” and “(()”. For the second combination “()”, we can add another(to it since the count of open parenthesis will be less than ‘N’. We can’t add)as we don’t have an equivalent open parenthesis, so our list of combinations will be: “(((”, “(()”, ()(“ - Following the same approach, next we will get the following list of combinations: “((()”, “(()(”, “(())”, “()((”, “()()”
- Next we will get: “((())”, “(()()”, “(())(”, “()(()”, “()()(”
- Finally, we will have the following combinations of balanced parentheses: “((()))”, “(()())”, “(())()”, “()(())”, “()()()”
- We can’t add more parentheses to any of the combinations, so we stop here.
Here is the visual representation of this algorithm:
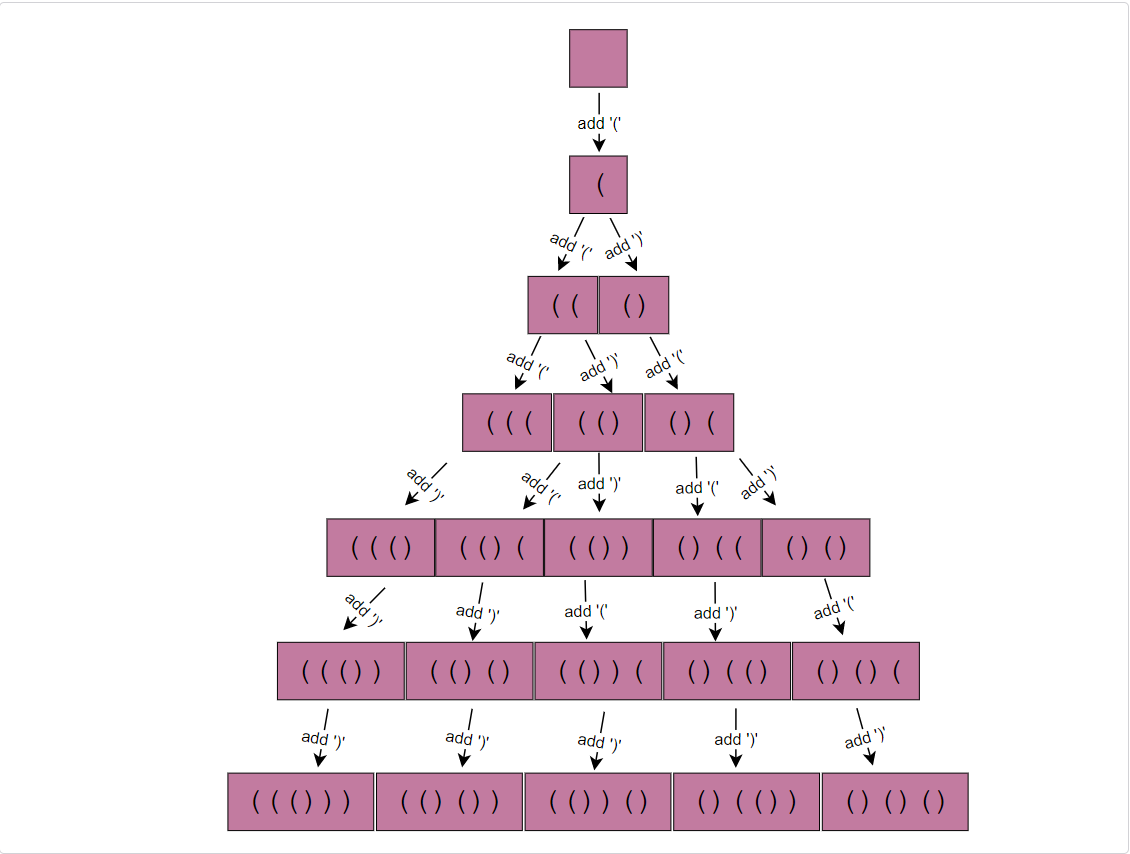
Code
Here is what our algorithm will look like:
1 | from collections import deque |
Time complexity
Let’s try to estimate how many combinations we can have for ‘N’ pairs of balanced parentheses. If we don’t care for the ordering - that ) can only come after ( - then we have two options for every position, i.e., either put open parentheses or close parentheses. This means we can have a maximum of 2^N combinations. Because of the ordering, the actual number will be less than 2^N.
If you see the visual representation of Example-2 closely you will realize that, in the worst case, it is equivalent to a binary tree, where each node will have two children. This means that we will have 2^N leaf nodes and 2^N-1 intermediate nodes. So the total number of elements pushed to the queue will be 2^N + 2^N-1, which is asymptotically equivalent to O(2^N). While processing each element, we do need to concatenate the current string with ( or ). This operation will take O(N), so the overall time complexity of our algorithm will be O(N2^N)*. This is not completely accurate but reasonable enough to be presented in the interview.
The actual time complexity O(4n/√n)* is bounded by the Catalan number and is beyond the scope of a coding interview. See more details here.
Space complexity
All the additional space used by our algorithm is for the output list. Since we can’t have more than O(2^N) combinations, the space complexity of our algorithm is O(N \2^N)*.
Recursive Solution
Here is the recursive algorithm following a similar approach:
1 | class Solution: |
#Unique Generalized Abbreviations (hard)
Leetcode 320 Design Gurus Educative.io
Problem Statement
Given a word, write a function to generate all of its unique generalized abbreviations.
A generalized abbreviation of a word can be generated by replacing each substring of the word with the count of characters in the substring. Take the example of “ab” which has four substrings: “”, “a”, “b”, and “ab”. After replacing these substrings in the actual word by the count of characters, we get all the generalized abbreviations: “ab”, “1b”, “a1”, and “2”.
Note: All contiguous characters should be considered one substring, e.g., we can’t take “a” and “b” as substrings to get “11”; since “a” and “b” are contiguous, we should consider them together as one substring to get an abbreviation “2”.
Example 1:
1 | Input: "BAT" |
Example 2:
1 | Input: "code" |
Constraints:
1 <= word.length <= 15wordconsists of only lowercase English letters.
Solution
This problem follows the Subsets pattern and can be mapped to Balanced Parentheses. We can follow a similar BFS approach.
Let’s take Example-1 mentioned above to generate all unique generalized abbreviations. Following a BFS approach, we will abbreviate one character at a time. At each step we have two options:
- Abbreviate the current character, or
- Add the current character to the output and skip abbreviation.
Following these two rules, let’s abbreviate BAT:
- Start with an empty word: “”
- At every step, we will take all the combinations from the previous step and apply the two abbreviation rules to the next character.
- Take the empty word from the previous step and add the first character to it. We can either abbreviate the character or add it (by skipping abbreviation). This gives us two new words:
_,B. - In the next iteration, let’s add the second character. Applying the two rules on
_will give us_ _and1A. Applying the above rules to the other combinationBgives usB_andBA. - The next iteration will give us:
_ _ _,2T,1A_,1AT,B _ _,B1T,BA_,BAT - The final iteration will give us:
3,2T,1A1,1AT,B2,B1T,BA1,BAT
Here is the visual representation of this algorithm:
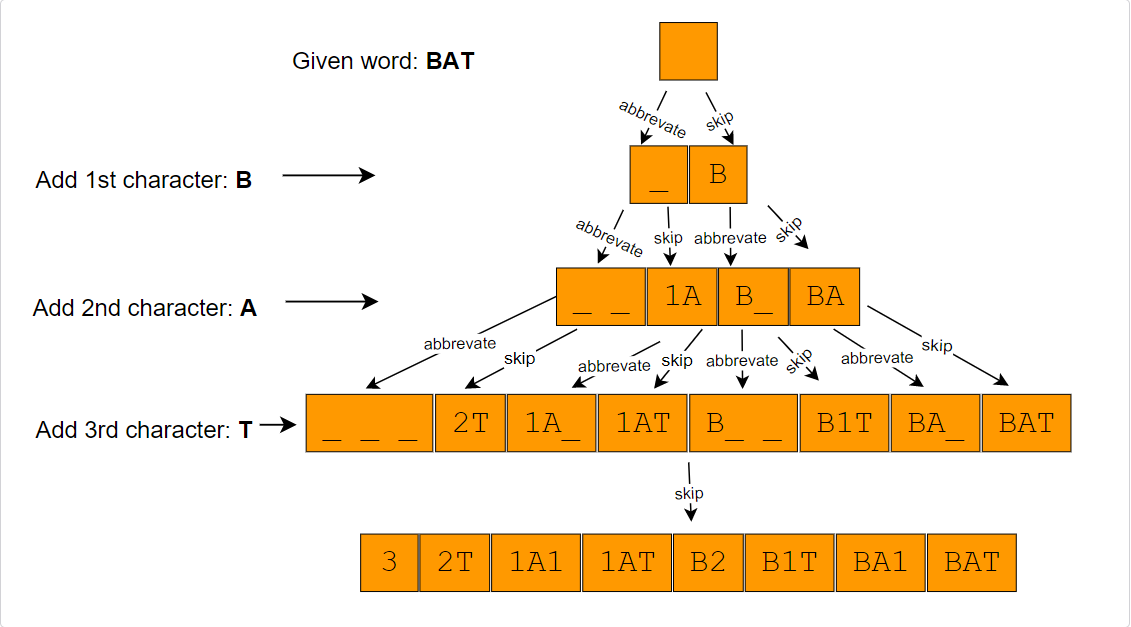
Code
Here is what our algorithm will look like:
1 | from collections import deque |
Time complexity
Since we had two options for each character, we will have a maximum of 2^N combinations. If you see the visual representation of Example-1 closely you will realize that it is equivalent to a binary tree, where each node has two children. This means that we will have 2^N leaf nodes and 2^N-1 intermediate nodes, so the total number of elements pushed to the queue will be 2^N + 2^N-1, which is asymptotically equivalent to O(2^N). While processing each element, we do need to concatenate the current string with a character. This operation will take O(N), so the overall time complexity of our algorithm will be O(N\2^N)*.
Space complexity
All the additional space used by our algorithm is for the output list. Since we can’t have more than O(2^N) combinations, the space complexity of our algorithm is O(N2^N)*.
Recursive Solution
Here is the recursive algorithm following a similar approach:
1 | class Solution: |
*Problem Challenge 1
241. Different Ways to Add Parentheses Design Gurus Educative.io
Evaluate Expression (hard)
Given an expression containing digits and operations (+, -, *), find all possible ways in which the expression can be evaluated by grouping the numbers and operators using parentheses.
Example 1:
1 | Input: "1+2*3" |
Example 2:
1 | Input: "2*3-4-5" |
Solution
This problem follows the Subsets pattern and can be mapped to Balanced Parentheses. We can follow a similar BFS approach.
Let’s take Example-1 mentioned above to generate different ways to evaluate the expression.
- We can iterate through the expression character-by-character.
- we can break the expression into two halves whenever we get an operator (+, -, *).
- The two parts can be calculated by recursively calling the function.
- Once we have the evaluation results from the left and right halves, we can combine them to produce all results.
Code
Here is what our algorithm will look like:
1 | class Solution: |
Time complexity
The time complexity of this algorithm will be exponential and will be similar to Balanced Parentheses. Estimated time complexity will be O(N\2^N)* but the actual time complexity O(4n/√n) is bounded by the Catalan number and is beyond the scope of a coding interview. See more details here.
Space complexity
The space complexity of this algorithm will also be exponential, estimated at O(2^N) though the actual will be O(4n/√n).
Memoized version
The problem has overlapping subproblems, as our recursive calls can be evaluating the same sub-expression multiple times. To resolve this, we can use memoization and store the intermediate results in a HashMap. In each function call, we can check our map to see if we have already evaluated this sub-expression before. Here is the memoized version of our algorithm; please see highlighted changes:
1 | class Solution: |
Problem Challenge 2
95. Unique Binary Search Trees II Design Gurus Educative.io
Structurally Unique Binary Search Trees (hard)
Given a number ‘n’, write a function to return all structurally unique Binary Search Trees (BST) that can store values 1 to ‘n’?
Example 1:
1 | Input: 2 |
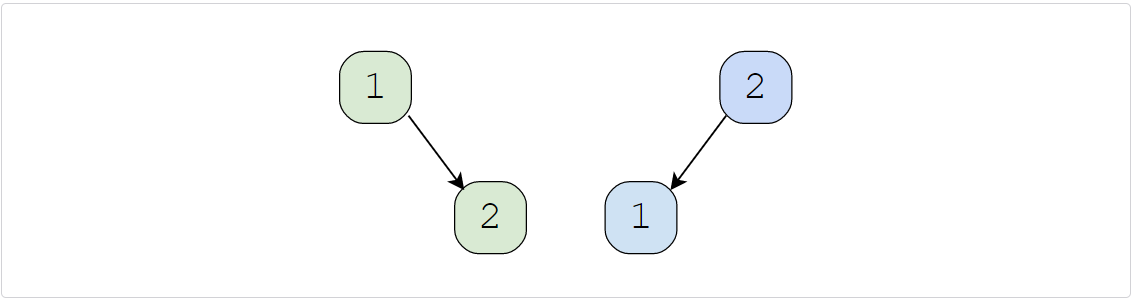
Example 2:
1 | Input: 3 |
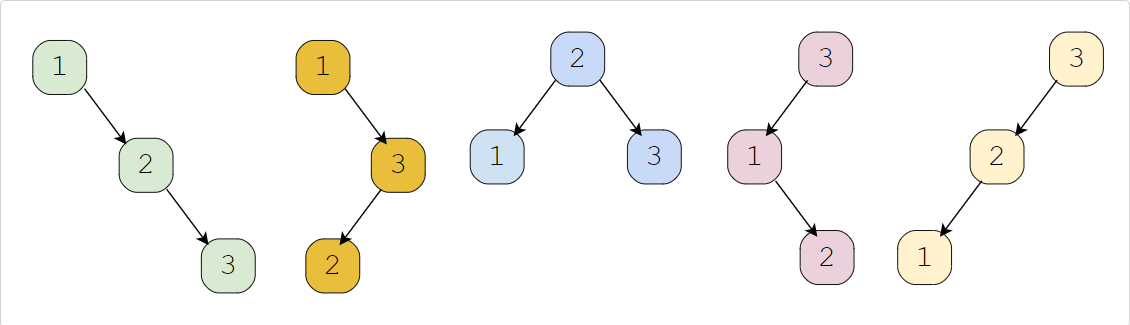
Constraints:
1 <= n <= 19
Solution
This problem follows the Subsets pattern and is quite similar to Evaluate Expression. Following a similar approach, we can iterate from 1 to ‘n’ and consider each number as the root of a tree. All smaller numbers will make up the left sub-tree and bigger numbers will make up the right sub-tree. We will make recursive calls for the left and right sub-trees
Code
Here is what our algorithm will look like:
1 | # class TreeNode: |
Time complexity
The time complexity of this algorithm will be exponential and will be similar to Balanced Parentheses. Estimated time complexity will be O(n\2^n)* but the actual time complexity O(4n/√n) is bounded by the Catalan number and is beyond the scope of a coding interview. See more details here.
Space complexity
The space complexity of this algorithm will be exponential too, estimated at O(2^n), but the actual will be O(4n/√n).
Memoized version
Since our algorithm has overlapping subproblems, can we use memoization to improve it? We could, but every time we return the result of a subproblem from the cache, we have to clone the result list because these trees will be used as the left or right child of a tree. This cloning is equivalent to reconstructing the trees, therefore, the overall time complexity of the memoized algorithm will also be the same.
Problem Challenge 3
96. Unique Binary Search Trees Design Gurus Educative.io
Count of Structurally Unique Binary Search Trees (hard)
Given a number ‘n’, write a function to return the count of structurally unique Binary Search Trees (BST) that can store values 1 to ‘n’.
Example 1:
1 | Input: 2 |
Example 2:
1 | Input: 3 |
Constraints:
1 <= n <= 8
Solution
This problem is similar to Structurally Unique Binary Search Trees. Following a similar approach, we can iterate from 1 to ‘n’ and consider each number as the root of a tree and make two recursive calls to count the number of left and right sub-trees.
Code
Here is what our algorithm will look like:
1 | # 这道题和上道题有一点区别,这道题只是要求返回个数就可以。 |
Time complexity
The time complexity of this algorithm will be exponential and will be similar to Balanced Parentheses. Estimated time complexity will be O(n2^n)O(n∗2n) but the actual time complexity O(4n/√n)* is bounded by the Catalan number and is beyond the scope of a coding interview. See more details here.
Space complexity
The space complexity of this algorithm will be exponential too, estimated O(2^n) but the actual will be O(4n/√n).
Memoized version
Our algorithm has overlapping subproblems as our recursive call will be evaluating the same sub-expression multiple times. To resolve this, we can use memoization and store the intermediate results in a HashMap. In each function call, we can check our map to see if we have already evaluated this sub-expression before. Here is the memoized version of our algorithm, please see highlighted changes:
1 | # class TreeNode: |