
Introduction to Trie
Introduction to Trie
A Trie, short for retrieval, is a specialized tree-based data structure primarily used for efficient storing, searching, and retrieval of strings over a given alphabet. It excels in scenarios where a large collection of strings needs to be managed and pattern-matching operations need to be performed with optimal efficiency.
Defining a Trie
A Trie, often referred to as a prefix tree, is constructed to represent a set of strings where each node in the tree corresponds to a single character of a string. The path from the root node to a particular node represents the characters of a specific string. This structural characteristic allows Tries to effectively share common prefixes among strings, leading to efficient storage and retrieval.
In the context of a Trie, the given strings are typically formed from a fixed alphabet. Each edge leading from a parent node to its child node corresponds to a character from the alphabet. By following the path of characters from the root to a specific node, we can reconstruct the string associated with that path.
Let’s look at the below Trie diagram.
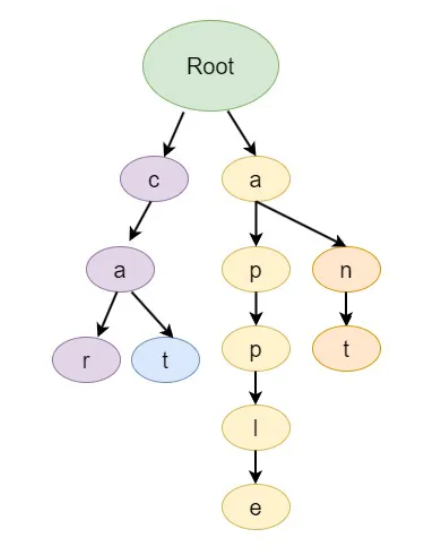
In the above Trie, car and cat shares the common prefix, and apple and ant shares the common prefix.
Need for Trie Data Structure?
Tries are commonly employed in applications such as spell checking, autocomplete suggestions, and searching within dictionaries or databases. They excel at these tasks because they minimize the search complexity in proportion to the length of the target string, making them significantly more efficient than other data structures like binary search trees.
Advantages of Using Tries
- Fast Pattern Matching: Tries provide rapid pattern matching queries, taking time proportional to the length of the pattern (or the string being searched).
- Common Prefix Sharing: Strings with common prefixes share nodes in the Trie, leading to efficient memory utilization and reduced redundancy.
- Efficient Insertion and Deletion: Tries are amenable to dynamic operations like insertion and deletion, while maintaining efficient search times. Alphabet Flexibility: Tries can handle various alphabets, making them versatile for a range of applications.
- Word Frequency Counting: Tries can be extended to store additional information at nodes, such as the frequency of words or strings.
In comparison to using a binary search tree, where a well-balanced tree would require time proportional to the product of the maximum string length and the logarithm of the number of keys, Tries offer the advantage of a search time linearly dependent on the length of the string being searched. This results in an optimization of search operations, especially when dealing with large datasets.
In summary, a Trie is a powerful data structure that optimizes string-related operations by efficiently storing and retrieving strings with shared prefixes. Its unique structure and fast search capabilities make it an invaluable tool in various text-based applications.
Properties of the Trie Data Structure
Trie is a tree-like data structure. So, it’s important to know the properties of Trie.
- Single Root Node: Every trie has one root node, serving as the starting point for all strings stored within.
- Node as a String: In a trie, each node symbolizes a string, with the path from the root to that node representing the string in its entirety.
- Edges as Characters: The edges connecting nodes in a trie represent individual characters. This means that traversing an edge essentially adds a character to the string.
- Node Structure: Nodes in a trie typically contain either hashmaps or arrays of pointers. Each position in this array or hashmap corresponds to a character. Additionally, nodes have a flag to signify if a string concludes at that particular node.
- Character Limitation: While tries can accommodate a vast range of characters, for the purpose of this discussion, we’re focusing on lowercase English alphabets (a-z). This means each node will have 26 pointers, with the 0th pointer representing ‘a’ and the 25th one representing ‘z’.
- Path Equals Word: In a trie, any path you trace from the root node to another node symbolizes a word or a string. This makes it easy to identify and retrieve strings.
These properties underline the essence of the trie data structure, emphasizing its efficiency and utility in managing strings, especially when dealing with large datasets.
Implementation of Tries
Let’s start by understanding the basic implementation of a Trie. Each node in a Trie can have multiple children, each representing a character. To illustrate this, consider the following simple Trie structure:
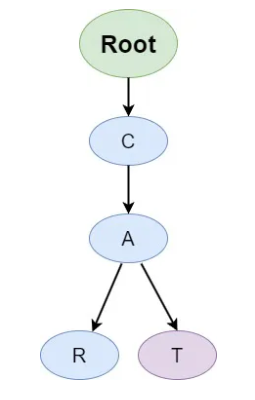
Here’s a step-by-step guide to implement a Trie:
- The Trie starts from the root node.
- The path from the root to the node “c” represents the character “c.”
- The path from “c” to “a” represents the string “ca,” and from “a” to “r” represents the string “car.”
- The path from “c” to “a” represents the string “ca,” and from “a” to “t” represents the string “cat.”
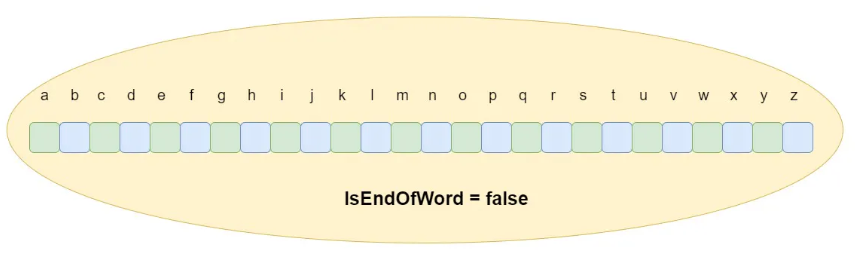
Representation of Trie Node
The Trie node has an array or list of children nodes, typically of size 26 to represent the English lowercase alphabets (a-z). Additionally, there’s a boolean flag isEndOfWord to indicate whether the current node marks the end of a word in the Trie.
1 | class TrieNode: |
Now, let’s look at the basic operations such as insertion, searching, and deletion on the Trie data structure.
Insertion in Trie Data Structure
Insertion in a Trie involves adding a string to the Trie, character by character, starting from the root. If the character already exists in the Trie, we move to the next node; otherwise, we create a new node for the character.
Algorithm
- Start from the root node.
- For each character in the string:
- Check if the character exists in the current node’s children.
- If it exists, move to the corresponding child node.
- If it doesn’t exist, create a new node for the character and link it to the current node.
- Move to the newly created node.
- After processing all characters in the string, mark the current node as the end of the word.
Example
Consider that we need to insert the ‘can’, ‘cat’, ‘cant’, and ‘apple’ into the trie. We insert them in the following order:
- Initial Trie:
1 | Root |
- Insert ‘can’:
1 | Root |
Explanation: Starting from the root, we add nodes for each character in “can”.
- Insert ‘cat’:
1 | Root |
Explanation: “cat” shares the first two characters with “can”, so we just add a new branch for the ‘t’ after ‘a’.
- Insert ‘cant’:
1 | Root |
Explanation: “cant” extends from the path of “can”, so we add a new node for ‘t’ after the existing ‘n’.
- Insert ‘apple’:
1 | Root |
Explanation: Starting from the root, we add nodes for each character in “apple” branching from the ‘a’ node.
Code
1 | class TrieNode: |
Complexity Analysis
Time Complexity: O(n) - Where n is the length of the word. This is when the word doesn’t share any prefix with the words already in the Trie or is longer than any word in the Trie.
Space Complexity:
- Best Case: O(1) - When the word is entirely a prefix of an existing word or shares a complete prefix with words in the Trie.
- Worst Case: O(n) - When the word doesn’t share any characters with the words in the Trie.
Searching in Trie Data Structure
Searching into Trie is similar to the insertion into the Trie. Let’s look at the below algorithm to search in the Trie data structure.
Algorithm
- Start from the root node.
- For each character in the word: a. Calculate its index (e.g., ‘a’ is 0, ‘b’ is 1, …). b. Check if the corresponding child node exists. c. If it exists, move to the child node and continue. d. If it doesn’t exist, return false (word not found).
- After processing all characters, check the
isEndOfWordflag of the current node. If it’s true, the word exists in the Trie; otherwise, it doesn’t.
Code
1 | class TrieNode: |
Complexity Analysis
Time Complexity: O(n) - Where n is the length of the word. This happens when you have to traverse the Trie to the deepest level.
Space Complexity: O(1) - Searching doesn’t require any additional space as it’s just about traversing the Trie.
Deletion in Trie Data Structure
When we delete a key in a Trie, there are three cases to consider:
- Key is a leaf node: If the key is a leaf node, we can simply remove it from the Trie.
- Key is a prefix of another key: If the key is a prefix of another key in the Trie, then we cannot remove it entirely. Instead, we just unmark the isEndOfWord flag.
- Key has children: If the key has children, we need to recursively delete the child nodes. If a child node becomes a leaf node after the deletion of the key, we can remove the child node as well.
Algorithm
- Initialization:
- Start from the root of the Trie.
- Begin with the first character of the word you want to delete.
- Base Case:
- If you’ve reached the end of the word:
- Check if the current node has the
isEndOfWordflag set to true. If not, the word doesn’t exist in the Trie, so return false. - If the flag is true, unset it. This means the word is no longer recognized as a word in the Trie.
- Check if the current node has any children. If it doesn’t, it means this node doesn’t contribute to any other word in the Trie, so it can be safely deleted. Return true to indicate to its parent that it can be removed.
- Check if the current node has the
- If you’ve reached the end of the word:
- Recursive Case:
- For the current character in the word:
- Calculate its index (e.g., ‘a’ is 0, ‘b’ is 1, …).
- Check if the corresponding child node exists. If it doesn’t, the word is not present in the Trie, so return false.
- If the child node exists, make a recursive call to the delete function with the child node and the next character in the word.
- For the current character in the word:
- Post-Recursive Handling:
- After the recursive call, check the return value:
- If it’s true, it means the child node can be deleted. Remove the reference to the child node.
- Check the current node. If it doesn’t have any other children and its
isEndOfWordflag is not set, it means this node doesn’t contribute to any word in the Trie. Return true to indicate to its parent that it can be removed. - If the node has other children or its
isEndOfWordflag is set, return false.
- After the recursive call, check the return value:
- Completion:
- Once all characters in the word have been processed, the word will either be deleted from the Trie (if it existed) or the Trie will remain unchanged (if the word didn’t exist).
Code
1 | class TrieNode: |
Complexity Analysis
Time Complexity: O(n) - Where n is the length of the word. This is when you have to traverse the Trie to the deepest level and potentially backtrack to delete nodes.
Space Complexity: O(1) - Deletion, like searching, doesn’t require any additional space.
Implement Trie (Prefix Tree)
Top Interview 150 | 208. Implement Trie (Prefix Tree) Design Gurus
Problem Statement
Design and implement a Trie (also known as a Prefix Tree). A trie is a tree-like data structure that stores a dynamic set of strings, and is particularly useful for searching for words with a given prefix.
Implement the Solution class:
Solution()Initializes the object.void insert(word)Insertswordinto the trie, making it available for future searches.bool search(word)Checks if the word exists in the trie.bool startsWith(word)Checks if any word in the trie starts with the given prefix.
Examples
- Example 1:
- Input:
- Trie operations:
["Trie", "insert", "search", "startsWith"] - Arguments:
[[], ["apple"], ["apple"], ["app"]]
- Trie operations:
- Expected Output:
[-1, -1, 1, 1] - Justification: After inserting “apple”, “apple” exists in the Trie. There is also a word that starts with “app”, which is “apple”.
- Input:
- Example 2:
- Input:
- Trie operations:
["Trie", "insert", "search", "startsWith", "search"] - Arguments:
[[], ["banana"], ["apple"], ["ban"], ["banana"]]
- Trie operations:
- Expected Output:
[-1, -1, 0, 1, 1] - Justification: After inserting “banana”, “apple” does not exist in the Trie but a word that starts with “ban”, which is “banana”, does exist.
- Input:
- Example 3:
- Input:
- Trie operations:
["Trie", "insert", "search", "search", "startsWith"] - Arguments:
[[], ["grape"], ["grape"], ["grap"], ["gr"]]
- Trie operations:
- Expected Output:
[-1, -1, 1, 1, 1] - Justification: After inserting “grape”, “grape” exists in the Trie. There are words that start with “grap” and “gr”, which is “grape”.
- Input:
Constraints:
1 <= word.length, prefix.length <= 2000wordand prefixconsist only of lowercase English letters.- At most 3 * 104 calls in total will be made to insert, search, and startsWith.
Solution
The trie is represented as a tree, where each node contains an array of pointers (or references) to its children and a boolean flag indicating if the current node marks the end of a word. When inserting or searching for a word, we start at the root node and navigate through the tree character by character until we either finish the operation or determine the word doesn’t exist in the trie.
Now, let’s break down the operations:
- Insert:
- We begin at the root node.
- For every character in the word, check if there’s a child node for it.
- If the child node doesn’t exist, we create it.
- Navigate to the child node and repeat the process for the next character.
- Once the end of the word is reached, mark the current node as an endpoint of a word.
- Search:
- Starting at the root, traverse the trie character by character.
- For every character in the word, check if there’s a child node for it.
- If at any point there isn’t a child node for the character, the word doesn’t exist in the trie.
- If we can traverse the entire word and the last node is marked as an endpoint, the word exists in the trie.
- StartsWith:
- The operation is similar to the search, but we don’t need the last node to be an endpoint.
- If we can traverse the prefix without any missing nodes, there exists a word in the trie that starts with the given prefix.
Algorithm Walkthrough
Using Example 1:
["Trie", "insert", "search", "startsWith"][[], ["apple"], ["apple"], ["app"]]
- Create an empty Trie.
- Insert “apple”.
- Start from the root. For ‘a’, move to the child node or create one if it doesn’t exist.
- Move to ‘p’, then the next ‘p’, followed by ‘l’ and finally ‘e’. Mark ‘e’ as the end of a word.
- Search for “apple”.
- Start from the root and traverse nodes ‘a’ -> ‘p’ -> ‘p’ -> ‘l’ -> ‘e’. Since ‘e’ is marked as the end of a word, return true.
- Check if a word starts with “app”.
- Traverse nodes for ‘a’ -> ‘p’ -> ‘p’. All nodes exist, so return true.
Code
1 | # class TrieNode: |
Complexity Analysis
- Time Complexity:
- Insert: (O(m)), where (m) is the key length.
- Search and StartsWith: (O(m)) in the worst case scenario.
- Space Complexity: (O(n \times m)), where (n) is the number of inserted keys and (m) is the average key length.
Index Pairs of a String
Leetcode 会员 Design Gurus
Problem Statement
Given a string text and a list of strings words, identify all [i, j] index pairs such that the substring text[i...j] is in words.
These index pairs should be returned in ascending order, first by the start index, then by the end index. Find every occurrence of each word within the text, ensuring that overlapping occurrences are also identified.
Examples
- Input: text =
"bluebirdskyscraper", words =["blue", "bird", "sky"] - Expected Output:
[[0, 3], [4, 7], [8, 10]] - Justification: The word “blue” is found from index 0 to 3, “bird” from 4 to 7, and “sky” from 8 to 10 in the string.
- Input: text =
- Input: text =
"programmingisfun", words =["pro", "is", "fun", "gram"] - Expected Output:
[[0, 2], [3, 6], [11, 12], [13, 15]] - Justification: “pro” is found from 0 to 2, “gram” from 3 to 6, “is” from 11 to 12, and “fun” from 13 to 15.
- Input: text =
- Input: text =
"interstellar", words =["stellar", "star", "inter"] - Expected Output:
[[0, 4], [5, 11]] - Justification: “inter” is found from 0 to 4, and “stellar” from 5 to 11. “star” is not found.
- Input: text =
Constraints:
1 <= text.length <= 1001 <= words.length <= 201 <= words[i].length <= 50textandwords[i]consist of lowercase English letters.- All the strings of words are unique.
Solution
To solve this problem, we will use a trie data structure, which is particularly efficient for managing a set of strings and performing quick searches for patterns within a text. A trie, also known as a prefix tree, allows us to efficiently store and retrieve strings with a common prefix, making it ideal for our purpose of identifying substrings within a given text.
The approach involves two main phases: building the trie with the given list of words and then using it to find the index pairs in the text. The trie’s structure enables us to search for each word in the text in an optimized manner, significantly reducing the number of comparisons needed compared to brute force methods.
Step-by-Step Algorithm
- Initialize the Trie:
- Create a trie and insert all the words from the given list into it. This is done in the first part of the code.
- Search and Record Index Pairs:
- Iterate over each character in the text. This character will act as the starting point for potential matches.
- For each starting character, initiate a pointer
pat the root of the trie. - Then, iterate over the text starting from the current starting point until the end of the text. In each iteration:
- Check if the current character exists as a child of the current trie node pointed by
p. - If it does not exist, break out of the inner loop as no further matching is possible from this starting point.
- If it exists, move the pointer
pto this child node. - Check if the current node
pis a leaf node (indicated byp.isEndbeingtrue). If it is, it means a complete word from the list has been found. - Record the start and end indices of this word. The start index is the position of the starting character, and the end index is the current position in the text.
- Check if the current character exists as a child of the current trie node pointed by
- Continue this process for each character in the text to ensure all occurrences, including overlapping ones, are found.
Algorithm Walkthrough
Using the input text = "programmingisfun", words = ["pro", "is", "fun", "gram"]:
- Initialize the Trie with Words:
- “pro”, “is”, “fun”, and “gram” are inserted into the trie.
- Search and Record Index Pairs:
- Start at index 0 (
'p'in"programmingisfun"):- Pointer
pis at the root. Finds ‘p’, moves to ‘r’, then ‘o’.p.isEndistrueat ‘o’, so record [0, 2].
- Pointer
- At index 1 (
'r'), no match is found. - similarly, At index 2 (
'o'), no match is found. - At index 3 (
'g'):- Finds ‘g’, ‘r’, ‘a’, ‘m’.
p.isEndistrueat ‘m’, so record [3, 6].
- Finds ‘g’, ‘r’, ‘a’, ‘m’.
- At index 11 (
'i'):- Finds ‘i’, ‘s’.
p.isEndistrueat ‘s’, so record [11, 12].
- Finds ‘i’, ‘s’.
- At index 13 (
's'):- Finds ‘f’, ‘u’, ‘n’.
p.isEndistrueat ‘n’, so record [13, 15].
- Finds ‘f’, ‘u’, ‘n’.
- Start at index 0 (
- Compile Results:
- The results [[0, 2], [3, 6], [11, 12], [13, 15]] are compiled into the 2D array
ansand returned.
- The results [[0, 2], [3, 6], [11, 12], [13, 15]] are compiled into the 2D array
By following these steps, the algorithm efficiently locates all occurrences of the words in the text, including overlapping ones, using the trie structure for optimized searching.
Code
1 | class TrieNode: |
Time and Space Complexity Analysis
Time Complexity:
- Building the Trie: O(N \ L)*, where N is the number of words and L is the average length of these words.
- Finding Index Pairs: O(T^2), where T is the length of the text string.
- Overall: O(N \ L + T^2)*
Space Complexity:
- Trie Storage: O(N L)*, for storing N words each of average length L.
Design Add and Search Words Data Structure
Top Interview 150 | 211. Design Add and Search Words Data Structure Design Gurus
Problem Statement
Design a data structure that supports the addition of new words and the ability to check if a string matches any previously added word.
Implement the Solution class:
Solution()Initializes the object.void addWord(word)Insertswordinto the data structure, making it available for future searches.bool search(word)Checks if there is any word in the data structure that matchesword. The method returnstrueif such a match exists, otherwise returnsfalse.
Note: In the search query word, the character '.' can represent any single letter, effectively serving as a wildcard character.
Examples
Example 1:
Input:
1
2["Solution", "addWord", "addWord", "search", "search"]
[[], ["apple"], ["banana"], ["apple"], ["....."]]Expected Output:
1
[-1, -1, -1, 1, 1]
Justification: After adding the words “apple” and “banana”, searching for “apple” will return
truesince “apple” is in the data structure. Searching for “…..” will also returntrueas both “apple” and “banana” match the pattern.
Example 2:
Input:
1
2["Solution", "addWord", "addWord", "search", "search"]
[[], ["cat"], ["dog"], ["c.t"], ["d..g"]]Expected Output:
1
[-1, -1, -1, 1, 0]
Justification: “c.t” matches “cat” and “d..g” doesn’t matches “dog”.
Example 3:
Input:
1
2["Solution", "addWord", "search", "search"]
[[], ["hello"], ["h.llo"], ["h...o"]]Expected Output:
1
[-1, -1, 1, 0]
Justification: “h.llo” and “h…o” both match “hello”.
Constraints:
1 <= word.length <= 25wordinaddWordconsists of lowercase English letters.wordinsearchconsist of ‘.’ or lowercase English letters.- There will be at most 2 dots in word for search queries.
- At most 104 calls will be made to addWord and search.
Solution
The crux of the problem lies in efficiently inserting words and then searching for them, even if the query includes wildcards. To solve this, we utilize the trie (prefix tree) data structure. A trie is a tree-like structure that’s useful for storing a dynamic set of strings, especially when the dataset involves large numbers of queries on prefixes of strings. Each node of the trie can represent a character of a word, and the path from the root node to any node represents the word stored up to that point. The key operation for the wildcard is a recursive search, which allows us to explore multiple paths in the trie when we encounter the wildcard character.
1. Trie Data Structure: Every node of the trie contains multiple child nodes (one for each character of the alphabet). We start with a root node that represents an empty string. Each level of the trie represents the next character of a word.
2. Adding a Word: To insert a word into our trie, we begin at the root and traverse down the trie based on the characters in the word. If a particular character doesn’t have a corresponding child node in the current node, we create a new child node for that character. Once we’ve processed every character of the word, we mark the final node as the end of a valid word.
3. Searching: Searching for a word is similar to inserting, but with an additional consideration for the wildcard character (‘.’). If we encounter a ‘.’, we must consider all child nodes of the current node and recursively continue our search from each of them. If any of the paths result in a match, we return true. If we reach the end of a word without encountering any mismatches or premature ends, we’ve found a valid word in our trie.
This trie-based approach ensures efficient operations for both inserting and searching for words. In cases without wildcards, the search operation can be performed in linear time relative to the word’s length. However, with wildcards, the time complexity might increase, but the trie structure still ensures that we do this efficiently.
Algorithm Walkthrough
Given the word “apple” to insert and then search for “…..”:
- Start at the root node.
- For inserting “apple”:
- At ‘a’, move down or create a node if it doesn’t exist.
- At ‘p’, move down or create.
- Do the same for the next ‘p’, ‘l’, and ‘e’.
- Mark the last node (for ‘e’) as the end of a word.
- For searching “…..”:
- At the first ‘.’, check all child nodes and continue.
- Repeat for each ‘.’.
- If any path leads to a node that represents the end of a word, return
true.
Code
1 | # class TrieNode: |
Complexity Analysis
- Time Complexity:
- Insertion (addWord): O(n), where n is the length of the word. This is because each insertion operation runs in linear time with respect to the length of the word.
- Search: O(n * m) in the worst case, where n is the length of the word and m is the total number of nodes in the Trie. This happens when the search word contains dots (‘.’). However, for words without dots, the search is O(n).
- Space Complexity: O(m n), where m is the total number of Trie nodes and n is the average number of characters in the words. Each Trie node has up to 26 children (for each letter of the alphabet). In the worst case, when no nodes are shared, the space complexity is O(m n).
# Extra Characters in a String
2707. Extra Characters in a String Design Gurus
没咋看懂
Problem Statement
Given a string s and an array of words words. Break string s into multiple non-overlapping substrings such that each substring should be part of the words. There are some characters left which are not part of any substring.
Return the minimum number of remaining characters in s, which are not part of any substring after string break-up.
Examples
- Example 1:
- Input:
s = "amazingracecar",dictionary = ["race", "car"] - Expected Output:
7 - Justification: The string
scan be rearranged to form “racecar”, leaving ‘a’, ‘m’, ‘a’, ‘z’, ‘i’, ‘n’, ‘g’ as extra.
- Input:
- Example 2:
- Input:
s = "bookkeeperreading",dictionary = ["keep", "read"] - Expected Output:
9 - Justification: The words “keep” and “read” can be formed from
s, but ‘b’, ‘o’, ‘o’, ‘k’, ‘e’, ‘r’, ‘i’, ‘n’, ‘g’ are extra.
- Input:
- Example 3:
- Input:
s = "thedogbarksatnight",dictionary = ["dog", "bark", "night"] - Expected Output:
6 - Justification: The words “dog”, “bark”, and “night” can be formed, leaving ‘t’, ‘h’, ‘e’, ‘s’, ‘a’, ‘t’ as extra characters.
- Input:
Constraints:
1 <= str.length <= 501 <= dictionary.length <= 501 <= dictionary[i].length <= 50dictionary[i]andsconsists of only lowercase English lettersdictionarycontains distinct words
Solution
The solution approach utilizes a dynamic programming strategy combined with a trie data structure. The dynamic programming aspect allows for efficiently keeping track of the minimum extra characters required at each position in the string s. This is achieved by building a bottom-up solution, where we start from the end of the string and work our way towards the beginning, calculating the minimum extra characters required for each substring.
The trie data structure is used to efficiently find and match the words from the dictionary within the string s. The combination of these two methods ensures that the solution is both time-efficient and space-efficient, as it avoids redundant computations and efficiently manages the storage of the dictionary words.
Step-by-Step Algorithm
- Initialize Trie:
- Construct a trie using the words from the
dictionary. Each node in the trie represents a character, and a complete path from the root to a leaf node represents a word.
- Construct a trie using the words from the
- Dynamic Programming Array:
- Initialize a dynamic programming (DP) array,
dp, of lengthn + 1, wherenis the length of the strings. This array will store the minimum number of extra characters required for the substring starting from each index.
- Initialize a dynamic programming (DP) array,
- DP Calculation:
- Iterate backwards through the string
s:- Set
dp[start]todp[start + 1] + 1initially. This represents the case where the current character is considered an extra character. - For each
startposition, iterate through the string to check if a word in the trie can be formed starting from this position. - If the current substring matches a word in the trie (
node.isEndis true), updatedp[start]to be the minimum of its current value anddp[end + 1], whereendis the end of the matched word. This step ensures that we consider removing the matched word and count the rest as extra characters.
- Set
- Iterate backwards through the string
- Return Result:
- The value of
dp[0]gives the minimum number of extra characters in the entire strings.
- The value of
Algorithm Walkthrough
Let’s consider the input s = "bookkeeperreading", dictionary = ["keep", "read"]
- Trie Construction:
- Build the trie with “keep” and “read”.
- DP Initialization:
- Initialize
dparray of length 18 (since “bookkeeperreading” has 17 characters).
- Initialize
- DP Calculation:
- Start from index 16 (last character ‘g’):
- For each index, try to form a word from the trie. For example, at index 12, the word “read” can be formed.
- Update
dp[12]to be the minimum ofdp[12]anddp[16](which is the end of “read” + 1).
- Start from index 16 (last character ‘g’):
- Iterate Backwards:
- Continue this process for each character in
s. If a character does not form a word in the trie,dp[start]remainsdp[start + 1] + 1.
- Continue this process for each character in
- Final Result:
dp[0]will have the minimum extra characters after processing the entire string.
This approach systematically checks each substring of s against the trie, and the dynamic programming array efficiently keeps track of the minimum extra characters required. The use of a trie ensures that each substring check is done in an optimized manner, avoiding unnecessary recomputations.
Code
1 | class TrieNode: |
Time and Space Complexity Analysis
Time Complexity
- Trie Construction: (O(W * L)), where (W) is the number of words in the dictionary and (L) is the average length of these words.
- Dynamic Programming Calculation: (O(n^2)), where (n) is the length of the input string
s. - Total Time Complexity: (O(W * L + n^2)).
Space Complexity
- Trie Storage: (O(W * L)), for storing the words in the trie.
- Dynamic Programming Array: (O(n)), for the array used in dynamic programming.
- Total Space Complexity: (O(W * L + n)).
Search Suggestions System
1268. Search Suggestions System Design Gurus
不如暴力解法,看leetcode上之前用java写的
Problem Statement
Given a list of distinct strings products and a string searchWord.
Determine a set of product suggestions after each character of the search word is typed. Every time a character is typed, return a list containing up to three product names from the products list that have the same prefix as the typed string.
If there are more than 3 matching products, return 3 lexicographically smallest products. These product names should be returned in lexicographical (alphabetical) order.
Examples
- Example 1:
- Input: Products: [“apple”, “apricot”, “application”], searchWord: “app”
- Expected Output: [[“apple”, “apricot”, “application”], [“apple”, “apricot”, “application”], [“apple”, “application”]]
- Justification: For the perfix ‘a’, “apple”, “apricot”, and “application” match. For the prefix ‘ap’, “apple”, “apricot”, and “application” match. For the prefix ‘app’, “apple”, and “application” match
- Example 2:
- Input: Products: [“king”, “kingdom”, “kit”], searchWord: “ki”
- Expected Output: [[“king”, “kingdom”, “kit”], [“king”, “kingdom”, “kit”]]
- Justification: All products starting with “k” are “king”, “kingdom”, and “kit”. The list remains the same for the ‘ki’ prefix.
- Example 3:
- Input: Products: [“fantasy”, “fast”, “festival”], searchWord: “farm”
- Expected Output: [[“fantasy”, “fast”, “festival”], [“fantasy”, “fast”], [], []]
- Justification: Initially, “fantasy”, “fast”, and “festival” match ‘f’. Moving to ‘fa’, only “fantasy” and “fast” match. No product matches with “far”, and “farm”.
Constraints:
1 <= products.length <= 10001 <= products[i].length <= 3000- 1 <= sum(products[i].length) <= 2 * 10^4
- All the strings of products are unique.
products[i]consists of lowercase English letters.1 <= searchWord.length <= 1000searchWordconsists of lowercase English letters.
Solution
To solve this problem, We will use the trie data structure to store the list of products. The trie is built by inserting each product, where each node represents a character. This structure allows us to efficiently find products that share a common prefix.
After building the trie, we process the search word by checking each of its prefixes. For each prefix, we perform a depth-first search (DFS) starting from the node matching the end of the prefix. The DFS is designed to find up to three lexicographically up to 3 smallest words that start with the given prefix. This approach of using a trie combined with DFS for each prefix ensures that we can quickly and effectively generate the required list of product suggestions.
Step-by-Step Algorithm
- Build the Trie:
- Create a root node representing the starting point of the trie.
- For each product:
- Start from the root and for each character in the product, navigate to the corresponding child node. Create a new node if it doesn’t exist.
- Mark the node corresponding to the last character of the product as a word end.
- Process Each Prefix of the Search Word:
- Initialize an empty list to store the final suggestions for each prefix.
- For each character in the search word, form a prefix.
- Start from the root of the trie and navigate to the node corresponding to the last character of the current prefix.
- If the node for the current prefix doesn’t exist, add an empty list to the suggestions and move to the next prefix.
- DFS for Each Prefix:
- Upon reaching the node corresponding to the current prefix, perform a DFS.
- Initialize an empty buffer to store up to three products.
- Explore all possible paths from the current node. If a path leads to a node marked as a word end, add the corresponding product to the buffer.
- Stop the DFS when you have collected three products or explored all paths.
- Upon reaching the node corresponding to the current prefix, perform a DFS.
- Compile Suggestions:
- Add the buffer containing up to three products to the list of suggestions for the current prefix.
- Continue the process for the next prefix.
Algorithm Walkthrough for Example 3
- Input: Products = [“fantasy”, “fast”, “festival”], Search Word = “farm”
- Walkthrough:
- Building the Trie:
- Insert “fantasy”, “fast”, “festival” into the trie, creating nodes for each character.
- Mark the end of each word in the trie.
- Processing Prefixes:
- Prefix “f”: Node exists. Proceed to DFS.
- Prefix “fa”: Node exists. Proceed to DFS.
- Prefix “far”: Node does not exist. Add an empty list to suggestions and skip DFS.
- Prefix “farm”: Node does not exist. Add an empty list to suggestions and skip DFS.
- DFS for “f” and “fa”:
- For “f”: DFS finds “fantasy”, “fast”, “festival”. Add these to suggestions.
- For “fa”: DFS finds “fantasy”, “fast”. Add these to suggestions.
- Final Output:
- Suggestions: [[“fantasy”, “fast”, “festival”], [“fantasy”, “fast”], [], []].
- Building the Trie:
This walkthrough illustrates how the trie efficiently organizes the products, and the DFS ensures that only the top three lexicographical matches for each prefix are selected.
Code
1 | # class TrieNode: |
Time and Space Complexity Analysis
Time Complexity
- Building the Trie: (O(N x L)), where (N) is the number of products and (L) is the average length of the products.
- Searching for Each Prefix: (O(M x K)), where (M) is the length of the search word and (K) is the time taken for the DFS, which is limited to 3 (constant time). Overall, it’s approximately (O(M)).
Overall Time Complexity: O(N * L + M), combining the time to build the Trie and perform searches.
Space Complexity
- Trie Storage: (O(N x L)), as each product of average length (L) is stored in the trie.
- Search Results: (O(M)), as we store up to 3 suggestions for each character in the search word.
Overall, the space complexity is dominated by the trie storage, which is (O(N x L)).