
416. Partition Equal Subset Sum Design Gurus Educative.io
Introduction
Topological Sort is used to find a linear ordering of elements that have dependencies on each other. For example, if event ‘B’ is dependent on event ‘A’, ‘A’ comes before ‘B’ in topological ordering.
This pattern defines an easy way to understand the technique for performing topological sorting of a set of elements and then solves a few problems using it.
Let’s see this pattern in action.
*Topological Sort (medium)
Design Gurus Educative.io
Problem Statement
Topological Sort of a directed graph (a graph with unidirectional edges) is a linear ordering of its vertices such that for every directed edge (U, V) from vertex U to vertex V, U comes before V in the ordering.
Given a directed graph, find the topological ordering of its vertices.
Example 1:
1 | Input: Vertices=4, Edges=[3, 2], |
Example 2:
1 | Input: Vertices=5, Edges=[4, 2], |
Example 3:
1 | Input: Vertices=7, Edges=[6, 4], |
Solution
The basic idea behind the topological sort is to provide a partial ordering among the vertices of the graph such that if there is an edge from U to V then U≤V i.e., U comes before V in the ordering. Here are a few fundamental concepts related to topological sort:
- Source: Any node that has no incoming edge and has only outgoing edges is called a source.
- Sink: Any node that has only incoming edges and no outgoing edge is called a sink.
- So, we can say that a topological ordering starts with one of the sources and ends at one of the sinks.
- A topological ordering is possible only when the graph has no directed cycles, i.e. if the graph is a Directed Acyclic Graph (DAG). If the graph has a cycle, some vertices will have cyclic dependencies which makes it impossible to find a linear ordering among vertices.
To find the topological sort of a graph we can traverse the graph in a Breadth First Search (BFS) way. We will start with all the sources, and in a stepwise fashion, save all sources to a sorted list. We will then remove all sources and their edges from the graph. After the removal of the edges, we will have new sources, so we will repeat the above process until all vertices are visited.
Here is the visual representation of this algorithm for Example-3:
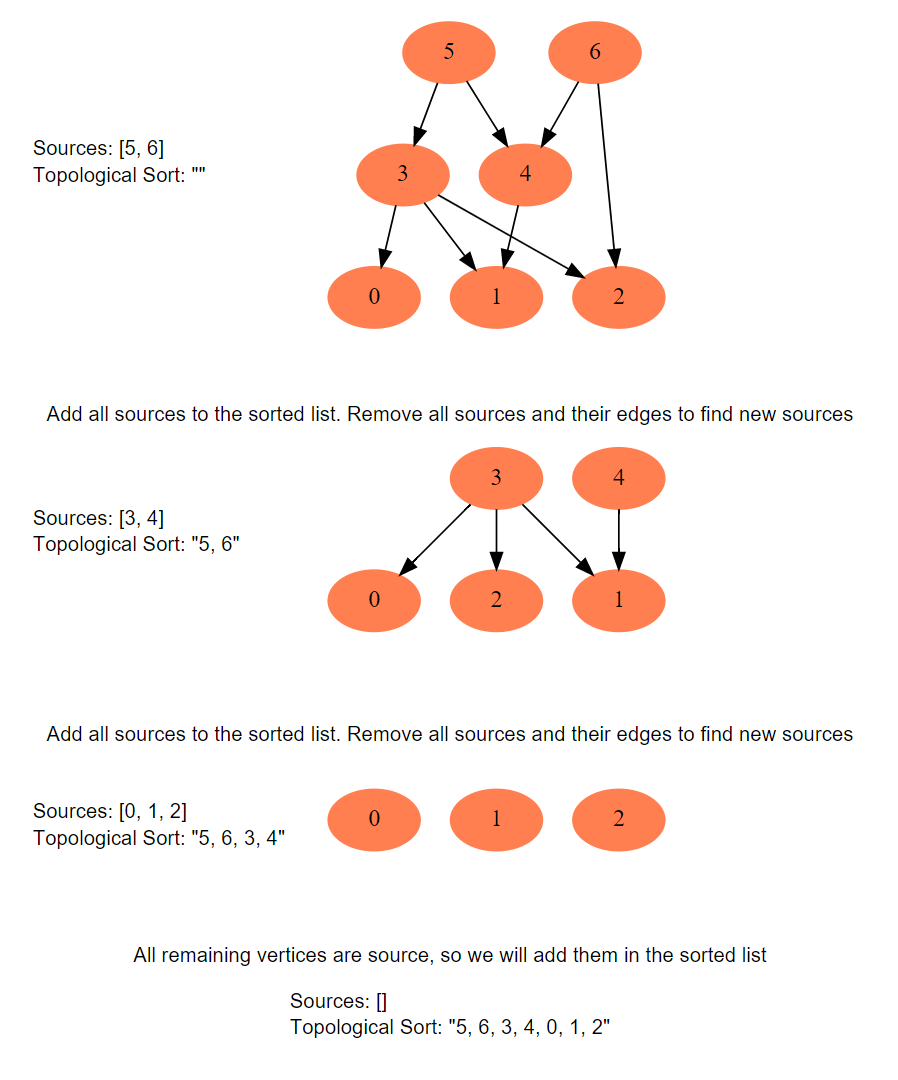
This is how we can implement this algorithm:
a. Initialization
- We will store the graph in Adjacency Lists, which means each parent vertex will have a list containing all of its children. We will do this using a HashMap where the ‘key’ will be the parent vertex number and the value will be a List containing children vertices.
- To find the sources, we will keep a HashMap to count the in-degrees i.e., count of incoming edges of each vertex. Any vertex with ‘0’ in-degree will be a source.
b. Build the graph and find in-degrees of all vertices
- We will build the graph from the input and populate the in-degrees HashMap.
c. Find all sources
- All vertices with ‘0’ in-degrees will be our sources and we will store them in a Queue.
d. Sort
- For each source, do the following things:
- Add it to the sorted list.
- Get all of its children from the graph.
- Decrement the in-degree of each child by 1.
- If a child’s in-degree becomes ‘0’, add it to the sources Queue.
- Repeat step 1, until the source Queue is empty.
Code
Here is what our algorithm will look like:
1 | from collections import deque |
Time Complexity
In step ‘d’, each vertex will become a source only once and each edge will be accessed and removed once. Therefore, the time complexity of the above algorithm will be O(V+E), where ‘V’ is the total number of vertices and ‘E’ is the total number of edges in the graph.
Space Complexity
The space complexity will be O(V+E), since we are storing all of the edges for each vertex in an adjacency list.
Similar Problems
Problem 1: Find if a given Directed Graph has a cycle in it or not.
Solution: If we can’t determine the topological ordering of all the vertices of a directed graph, the graph has a cycle in it. This was also referred to in the above code:
1 | if (sortedOrder.size() != vertices) // topological sort is not possible as the graph has a cycle |
Tasks Scheduling (medium)
Top Interview 150 | 207. Course Schedule Design Gurus Educative.io
Problem Statement
There are ‘N’ tasks, labeled from ‘0’ to ‘N-1’. Each task can have some prerequisite tasks which need to be completed before it can be scheduled. Given the number of tasks and a list of prerequisite pairs, find out if it is possible to schedule all the tasks.
Example 1:
1 | Input: Tasks=3, Prerequisites=[0, 1], [1, 2] |
Example 2:
1 | Input: Tasks=3, Prerequisites=[0, 1], |
Example 3:
1 | Input: Tasks=6, Prerequisites=[2, 5], [0, 5], [0, 4], [1, 4], [3, 2], [1, 3] |
Solution
This problem is asking us to find out if it is possible to find a topological ordering of the given tasks. The tasks are equivalent to the vertices and the prerequisites are the edges.
We can use a similar algorithm as described in Topological Sort to find the topological ordering of the tasks. If the ordering does not include all the tasks, we will conclude that some tasks have cyclic dependencies.
Code
Here is what our algorithm will look like (only the highlighted lines have changed):
1 | # 和上一题一摸一样 |
Time complexity
In step ‘d’, each task can become a source only once and each edge (prerequisite) will be accessed and removed once. Therefore, the time complexity of the above algorithm will be O(V+E), where ‘V’ is the total number of tasks and ‘E’ is the total number of prerequisites.
Space complexity
The space complexity will be O(V+E), since we are storing all of the prerequisites for each task in an adjacency list.
Similar Problems
Course Schedule: There are ‘N’ courses, labeled from ‘0’ to ‘N-1’. Each course can have some prerequisite courses which need to be completed before it can be taken. Given the number of courses and a list of prerequisite pairs, find if it is possible for a student to take all the courses.
Solution: This problem is exactly similar to our parent problem. In this problem, we have courses instead of tasks.
Tasks Scheduling Order (medium)
Top Interview 150 | 210. Course Schedule II Design Gurus Educative.io
Problem Statement
There are ‘N’ tasks, labeled from ‘0’ to ‘N-1’. Each task can have some prerequisite tasks which need to be completed before it can be scheduled. Given the number of tasks and a list of prerequisite pairs, write a method to find the ordering of tasks we should pick to finish all tasks.
Example 1:
1 | Input: Tasks=3, Prerequisites=[0, 1], [1, 2] |
Example 2:
1 | Input: Tasks=3, Prerequisites=[0, 1], |
Example 3:
1 | Input: Tasks=6, Prerequisites=[2, 5], [0, 5], [0, 4], [1, 4], [3, 2], [1, 3] |
Solution
This problem is similar to Tasks Scheduling, the only difference being that we need to find the best ordering of tasks so that it is possible to schedule them all.
Code
Here is what our algorithm will look like (only the highlighted lines have changed):
1 | from collections import deque |
Time complexity
In step ‘d’, each task can become a source only once and each edge (prerequisite) will be accessed and removed once. Therefore, the time complexity of the above algorithm will be O(V+E), where ‘V’ is the total number of tasks and ‘E’ is the total number of prerequisites.
Space complexity
The space complexity will be O(V+E), since we are storing all of the prerequisites for each task in an adjacency list.
Similar Problems
Course Schedule: There are ‘N’ courses, labeled from ‘0’ to ‘N-1’. Each course has some prerequisite courses which need to be completed before it can be taken. Given the number of courses and a list of prerequisite pairs, write a method to find the best ordering of the courses that a student can take in order to finish all courses.
Solution: This problem is exactly similar to our parent problem. In this problem, we have courses instead of tasks.
*All Tasks Scheduling Orders (hard)
Design Gurus Educative.io
Problem Statement
There are ‘N’ tasks, labeled from ‘0’ to ‘N-1’. Each task can have some prerequisite tasks which need to be completed before it can be scheduled. Given the number of tasks and a list of prerequisite pairs, write a method to print all possible ordering of tasks meeting all prerequisites.
Example 1:
1 | Input: Tasks=3, Prerequisites=[0, 1], |
Example 2:
1 | Input: Tasks=4, Prerequisites=[3, 2], |
Example 3:
1 | Input: Tasks=6, Prerequisites=[2, 5], [0, 5], [0, 4], [1, 4], [3, 2], [1, 3] |
Solution
This problem is similar to Tasks Scheduling Order the only difference is that we need to find all the topological orderings of the tasks.
At any stage, if we have more than one source available and since we can choose any source, therefore, in this case, we will have multiple orderings of the tasks. We can use a recursive approach with Backtracking to consider all sources at any step.
Code
Here is what our algorithm will look like:
1 | from collections import deque |
Time and Space Complexity
If we don’t have any prerequisites, all combinations of the tasks can represent a topological ordering. As we know, that there can be N!N! combinations for ‘N’ numbers, therefore the time and space complexity of our algorithm will be O(V! E)* where ‘V’ is the total number of tasks and ‘E’ is the total prerequisites. We need the ‘E’ part because in each recursive call, at max, we remove (and add back) all the edges.
*Alien Dictionary (hard)
没咋看懂题目:应该是对于给定的单词列表,相邻的单词对比,找出第一个不同的字符,这个字符的顺序将定义一条有向边。
Leetcode 269 会员 Design Gurus Educative.io
Problem Statement
There is a dictionary containing words from an alien language for which we don’t know the ordering of the letters. Write a method to find the correct order of the letters in the alien language. It is given that the input is a valid dictionary and there exists an ordering among its letters.
Example 1:
1 | Input: Words: ["ba", "bc", "ac", "cab"] |
Example 2:
1 | Input: Words: ["cab", "aaa", "aab"] |
Example 3:
1 | Input: Words: ["ywx", "wz", "xww", "xz", "zyy", "zwz"] |
Constraints:
1 <= words.length <= 1001 <= words[i].length <= 100words[i]consists of only lowercase English letters.
Solution
Since the given words are sorted lexicographically by the rules of the alien language, we can always compare two adjacent words to determine the ordering of the characters. Take Example-1 above: [“ba”, “bc”, “ac”, “cab”]
- Take the first two words “ba” and “bc”. Starting from the beginning of the words, find the first character that is different in both words: it would be ‘a’ from “ba” and ‘c’ from “bc”. Because of the sorted order of words (i.e. the dictionary!), we can conclude that ‘a’ comes before ‘c’ in the alien language.
- Similarly, from “bc” and “ac”, we can conclude that ‘b’ comes before ‘a’.
These two points tell us that we are actually asked to find the topological ordering of the characters, and that the ordering rules should be inferred from adjacent words from the alien dictionary.
This makes the current problem similar to Tasks Scheduling Order, the only difference being that we need to build the graph of the characters by comparing adjacent words first, and then perform the topological sort for the graph to determine the order of the characters.
Code
Here is what our algorithm will look like (only the highlighted lines have changed):
1 | # 但是有一点不太懂就是为什么。只要选取相邻的两个就可以建立邻接表 |
Time complexity
In step ‘d’, each task can become a source only once and each edge (a rule) will be accessed and removed once. Therefore, the time complexity of the above algorithm will be O(V+E), where ‘V’ is the total number of different characters and ‘E’ is the total number of the rules in the alien language. Since, at most, each pair of words can give us one rule, therefore, we can conclude that the upper bound for the rules is O(N) where ‘N’ is the number of words in the input. So, we can say that the time complexity of our algorithm is O(V+N).
Space complexity
The space complexity will be O(V+N), since we are storing all of the rules for each character in an adjacency list.
*Problem Challenge 1
Leetcode 444 会员 Design Gurus Educative.io
Reconstructing a Sequence (hard)
Given a sequence originalSeq and an array of sequences, write a method to find if originalSeq can be uniquely reconstructed from the array of sequences.
Unique reconstruction means that we need to find if originalSeq is the only sequence such that all sequences in the array are subsequences of it.
Example 1:
1 | Input: originalSeq: [1, 2, 3, 4], seqs: [[1, 2], [2, 3], [3, 4]] |
Example 2:
1 | Input: originalSeq: [1, 2, 3, 4], seqs: [[1, 2], [2, 3], [2, 4]] |
Example 3:
1 | Input: originalSeq: [3, 1, 4, 2, 5], seqs: [[3, 1, 5], [1, 4, 2, 5]] |
Constraints:
- n == originalSeq.length
- 1 <= n <= 10^4
originalSeqis a permutation of all the integers in the range [1, n].- 1 <= seqs.length <= 10^4
- 1 <= seqs[i].length <= 10^4
- `1 <= sum(seqs[i].length) <= 10^5
1 <= seqs[i][j] <= n- All the arrays of sequences are unique.
seqs[i]is a subsequence of nums.
Try it yourself
Try solving this question here:
1 | # 我的想法:什么时候sources中的元素超过了1一个,那就是有有问题的,输出false |
Solution
Since each sequence in the given array defines the ordering of some numbers, we need to combine all these ordering rules to find two things:
- Is it possible to construct the
originalSeqfrom all these rules? - Are these ordering rules not sufficient enough to define the unique ordering of all the numbers in the
originalSeq? In other words, can these rules result in more than one sequence?
Take Example-1:
1 | originalSeq: [1, 2, 3, 4], seqs:[[1, 2], [2, 3], [3, 4]] |
The first sequence tells us that ‘1’ comes before ‘2’; the second sequence tells us that ‘2’ comes before ‘3’; the third sequence tells us that ‘3’ comes before ‘4’. Combining all these sequences will result in a unique sequence: [1, 2, 3, 4].
The above explanation tells us that we are actually asked to find the topological ordering of all the numbers and also to verify that there is only one topological ordering of the numbers possible from the given array of the sequences.
This makes the current problem similar to Tasks Scheduling Order with two differences:
- We need to build the graph of the numbers by comparing each pair of numbers in the given array of sequences.
- We must perform the topological sort for the graph to determine two things:
- Can the topological ordering construct the
originalSeq? - That there is only one topological ordering of the numbers possible. This can be confirmed if we do not have more than one source at any time while finding the topological ordering of numbers.
- Can the topological ordering construct the
Code
Here is what our algorithm will look like (only the highlighted lines have changed):
1 | # 我的想法是:什么时候sources中的元素超过了1一个,那就是有有问题的,输出false |
Time complexity
In step ‘d’, each number can become a source only once and each edge (a rule) will be accessed and removed once. Therefore, the time complexity of the above algorithm will be O(V+E), where ‘V’ is the count of distinct numbers and ‘E’ is the total number of the rules. Since, at most, each pair of numbers can give us one rule, we can conclude that the upper bound for the rules is O(N) where ‘N’ is the count of numbers in all sequences. So, we can say that the time complexity of our algorithm is O(V+N).
Space complexity
The space complexity will be O(V+N), since we are storing all of the rules for each number in an adjacency list.
*Problem Challenge 2
310. Minimum Height Trees Design Gurus Educative.io
Minimum Height Trees (hard)
We are given an undirected graph that has characteristics of a k-ary tree. In such a graph, we can choose any node as the root to make a k-ary tree. The root (or the tree) with the minimum height will be called Minimum Height Tree (MHT). There can be multiple MHTs for a graph. In this problem, we need to find all those roots which give us MHTs. Write a method to find all MHTs of the given graph and return a list of their roots.
Example 1:
1 | Input: vertices: 5, Edges: [[0, 1], [1, 2], [1, 3], [2, 4]] |
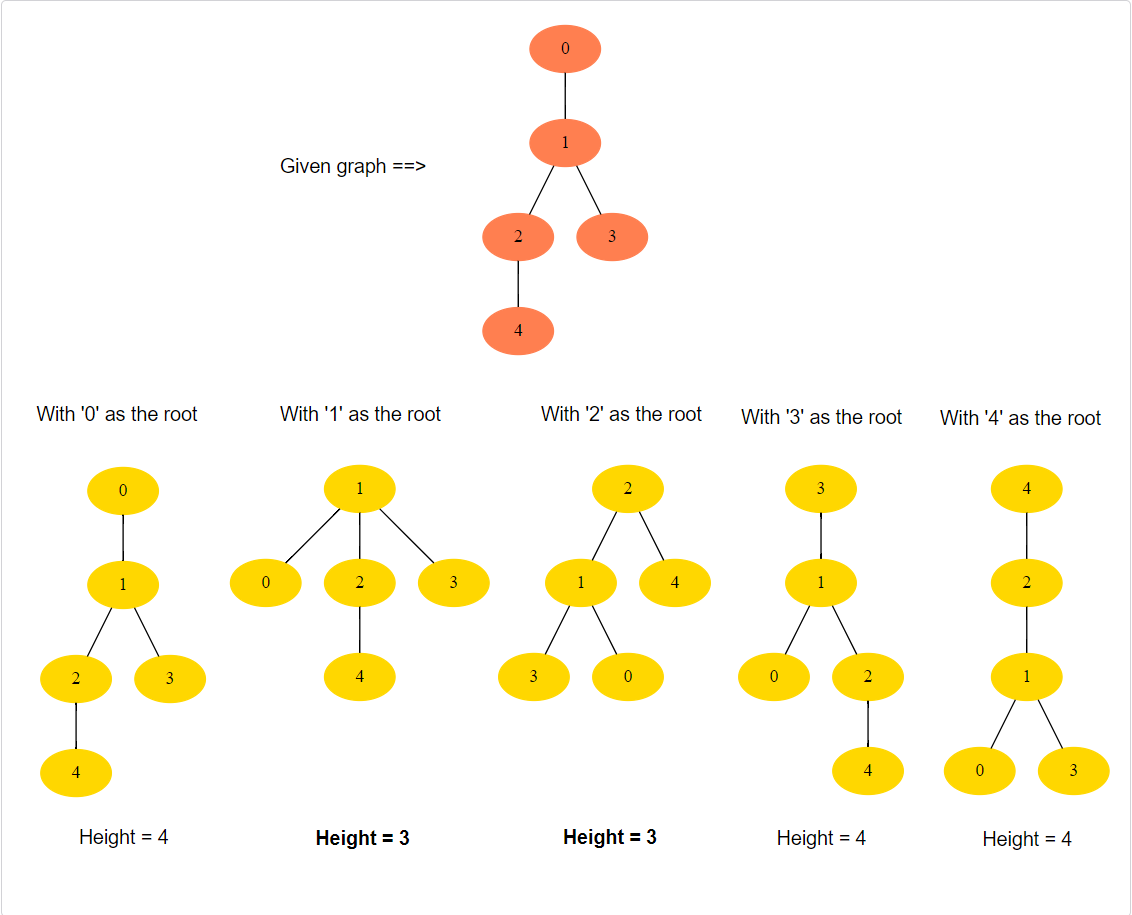
Example 2:
1 | Input: vertices: 4, Edges: [[0, 1], [0, 2], [2, 3]] |
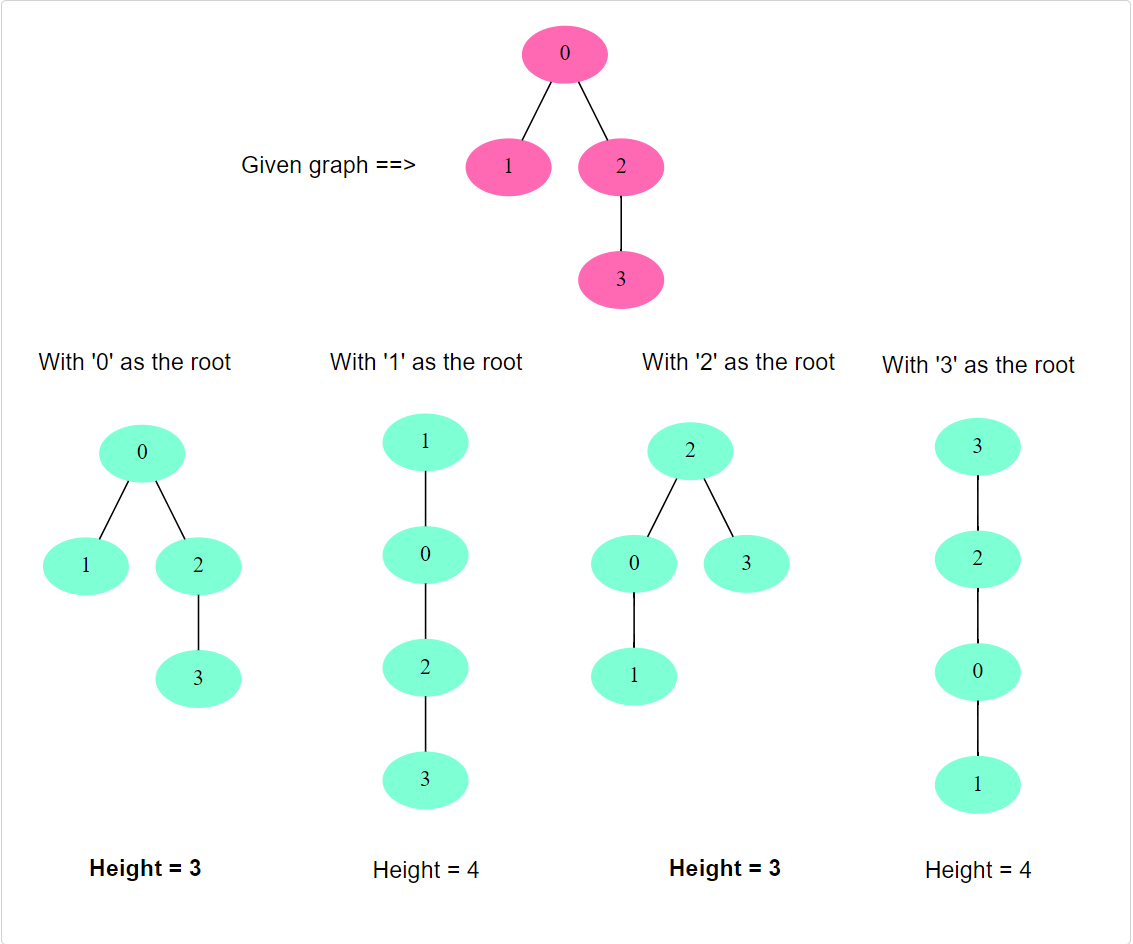
Example 3:
1 | Input: vertices: 4, Edges: [[0, 1], [1, 2], [1, 3]] |
Constraints:
- 1 <= vertices <= 2 * 10^4
- edges.length == n - 1
- 0 <= ai, bi < n
- ai != bi
- All the pairs (ai, bi) are distinct.
- The given input is guaranteed to be a tree and there will be no repeated edges.
Solution
The key intuition behind solving this problem is based on the definition of a tree’s height: the height of a tree is the number of edges on the longest path between the root and any leaf. So, an MHT is a tree that minimizes this longest path.
Imagine we have a longest path P in the tree. The path P has two ends; let’s call them end A and end B. Now, let’s consider what the root of an MHT can be:
- If we select a root that is not on the path P, the height of the tree would at least be the length of P, because there would be a path from the root to either A or B that is longer than P (as it includes P plus some additional edges). Therefore, the root of the MHT must be on P.
- If the root is on P, but not in the middle of P, then the height of the tree will be larger than if we selected the root in the middle of P, because the longest path will be from the root to either end of P. Therefore, the root of the MHT must be in the middle of P.
So, the problem of finding the MHT root(s) reduces to finding the middle node(s) of the longest path in the tree.
We can find the middle node(s) of the longest path by using an algorithm called ‘leaf pruining’. Let’s look into this.
From the above discussion, we can deduce that the leaves can’t give us MHT, hence, we can remove them from the graph and remove their edges too. Once we remove the leaves, we will have new leaves. Since these new leaves can’t give us MHT, we will repeat the process and remove them from the graph too. We will prune the leaves until we are left with one or two nodes which will be our answer and the roots for MHTs.
The algorithm works because when you trim leaves, you’re essentially trimming the ends of all the longest paths in the tree. If there’s one longest path, you’re trimming it from both ends, and if there are multiple longest paths, you’re trimming them all. Eventually, you’re left with one or two nodes, which must be the middle of the longest path(s), and those are the roots of the MHTs.
We can implement the above process using the topological sort. Any node with only one edge (i.e., a leaf) can be our source and, in a stepwise fashion, we can remove all sources from the graph to find new sources. We will repeat this process until we are left with one or two nodes in the graph, which will be our answer.
This Java algorithm is used to find the root nodes of the Minimum Height Trees (MHTs) in a graph. An MHT is a tree rooted at a specific node that minimizes the tree’s height. In a graph with ‘n’ nodes, there can be one or two MHTs.
Here’s a breakdown of the algorithm:
- It starts by checking if the number of nodes is less than or equal to 0, returning an empty list if true, as there would be no trees in the graph. If the graph contains only one node, it returns that single node as an MHT.
- Next, it initializes two HashMaps,
inDegreeto store the count of incoming edges for every vertex andgraphas an adjacency list representation of the graph. It populates these HashMaps with initial values. - The algorithm then constructs the graph. As it’s an undirected graph, each edge connects two nodes bi-directionally, meaning it adds a link for both nodes and increments the in-degrees of the two nodes.
- The algorithm finds all leaf nodes (nodes with only one in-degree) and adds them to a queue.
- Next, it iteratively removes the leaf nodes level by level, subtracting one from the in-degree of each leaf node’s children. If a child node becomes a leaf node as a result, it is added to the queue of leaf nodes. This process repeats until the graph has been reduced to one or two nodes, which represent the roots of the MHTs.
- Finally, the algorithm adds the remaining nodes in the leaves queue to
minHeightTreesand returns this list. These nodes are the roots of the MHTs in the graph.
Code
Here is what our algorithm will look like:
1 | from collections import deque |
Time complexity
In step ‘d’, each node can become a source only once and each edge will be accessed and removed once. Therefore, the time complexity of the above algorithm will be O(V+E), where ‘V’ is the total nodes and ‘E’ is the total number of the edges.
Space complexity
The space complexity will be O(V+E), since we are storing all of the edges for each node in an adjacency list.