
Introduction to Stack
Stack is a linear data structure that follows a particular order of operation. This order can either be Last In First Out (LIFO) or First In Last Out (FILO).
Imagine you have a pile of books that you plan to read. You keep adding books to the top of the pile. When you’re ready to start reading, you take a book from the top of the pile. The last book you added to the pile is the first one you read. That’s LIFO - the principle that stack data structures operate on.
What makes stacks so unique is their simplicity and elegance. Despite being straightforward, they can be incredibly powerful when used in the right way.
Real-world Examples of Stacks
Before diving into technicalities, let’s familiarize ourselves with stacks in our daily lives. Stacks are everywhere around us, even if we might not notice them. Here are some examples to help you relate:
- Stack of Books: This is perhaps the simplest example. A pile of books is a stack. The book on the top was the last one added and will be the first one removed.
- Stack of Plates: Picture a stack of plates at a buffet. The first plate you’ll take is the one on top, which was the last one put on the stack.
- Web Browser History: Every time you visit a new webpage, it’s added to the top of your history stack. When you hit the back button, you’re “popping” pages off the top of the stack.
- Undo Function in Software Applications: The undo function in software applications uses a stack to remember actions. The most recent action is on top and will be the first one undone.
Looking at these examples, it’s clear that stacks are not just a theoretical concept, but a practical one that we use unconsciously in our daily lives. With this understanding, let’s dive deeper into the operations that define stacks in data structures.

The LIFO Principle
As mentioned earlier, stacks in data structures operate on the Last-In, First-Out (LIFO) principle. This means that the last item added to the stack is the first one that gets taken out.
The LIFO principle is the heart of stack data structures. It governs how we add and remove elements, making stack operations predictable and consistent. With that, let’s explore the primary operations that you can perform on a stack.
There are four key operations that you can perform on a stack:
- Push: This is how we add an element to the stack. The element is always added to the top.
- Pop: This is the removal of an element from the stack. The element removed is always from the top.
- Peek or Top: This operation allows us to see the element on the top of the stack without removing it.
- IsEmpty: This operation checks if the stack is empty.
Let’s see these stack operations in detail in the next section.
Operations on Stack
This chapter aims to demystify the main operations involved in manipulating a stack: push, pop, peek, and isEmpty. We will examine these operations closely, detailing their functionality, providing coding examples, and highlighting their importance in problem-solving.
Push Operation
Let’s start with the push operation. As we’ve previously learned, push adds a new element to the top of the stack. Think of it like placing a new dish on top of a pile in your sink - the new dish (our data) is added to the top of the pile (our stack).
In programming, the push operation usually involves a few steps. First, we check if there’s room to add a new element (we’ll discuss this in more detail when we talk about stack overflow). If there’s room, we add the new element to the top of the stack.
Pop Operation
Next, we have the pop operation, which removes the topmost element of the stack. It’s like removing the top dish from our pile in the sink.
In code, popping an element from a stack is usually done in two parts. First, we check if there are any elements to remove (we’ll look at this more when we discuss stack underflow). If there are elements, we remove the top one.

Peek or Top Operation
The peek or top operation is slightly different. Instead of adding or removing an element, this operation allows us to look at the top element of the stack without removing it. It’s like looking at the top dish in our sink pile without touching it.
This operation can be handy when you need to know what’s on top of your stack, but you don’t want to change anything. It’s a read-only operation.
IsEmpty Operation
Finally, the isEmpty operation checks if the stack is empty. This operation is essential for preventing errors when popping an element from an empty stack (known as stack underflow).
An empty stack will return true when the isEmpty operation is performed, while a stack with one or more elements will return false.
Putting it All Together
Knowing how each of these operations works is crucial. But, what’s more important is knowing how to use them together to solve problems. Here’s a brief coding example to show how these operations can be used together.
1 | class Stack: |
Dealing with Stack Overflow and Underflow
As we discussed earlier, stack overflow and underflow are two situations you might encounter when working with stacks. Stack overflow occurs when you try to push an element onto a stack that’s already full, while stack underflow occurs when you try to pop an element from an empty stack.
Handling these situations properly is crucial to preventing runtime errors and ensuring that your code runs smoothly. Depending on the programming language and the specific implementation of the stack, you might have different ways of handling these situations. It’s always a good idea to check for stack overflow and underflow before performing push and pop operations.
Implementing Stack Data Structure
In this module, we’ll cover how to implement a stack data structure using different programming languages and data structures. This is where you’ll see how powerful, versatile, and useful stacks can be!
Stack Implementation Using an Array
Implementing a stack using an array is one of the most straightforward ways. Let’s see how you can do this in different programming languages:
1 | class Stack: |
The primary advantage of using an array for implementing a stack is that it’s simple and requires no additional setup. However, the size of the array can limit the stack size, leading to a stack overflow.
Stack Implementation Using Linked List
An alternative way of implementing a stack is by using a linked list. This method can overcome the size limitation issue present in the array implementation. The code will look something like this:
1 | class Stack: |
The key difference here is that we’re using a Node class to create nodes and linking them together to form a stack. This method allows our stack to be dynamically sized, avoiding the overflow issue we saw with arrays.
Here is how different programming languages implement the stack class:
| Language | API |
|---|---|
| Java | java.util.Stack |
| Python | Implemented through List |
| C++ | std::stack |
| JavaScript | Implemented through Array |
Applications of Stack
Now that we have gained a solid understanding of stack operations and their implementation, it’s time to bring it all together by exploring the real-world applications of stacks. This fascinating data structure has a multitude of uses across many different areas in computer science, from memory management and compiler design to problem-solving in data analysis. Let’s dive in!
Memory Management
One of the primary uses of stacks is in memory management. Ever wondered how your computer remembers which functions it’s running and in which order? The answer is stacks! When a function is called in a program, the system ‘pushes’ it onto a call stack. When the function finishes running, it’s ‘popped’ off the stack. This mechanism allows for nested function calls, where one function can call another.
This is also how recursion works in programming. When a function calls itself, each recursive call is added to the stack with its own set of variables. Once the base case is met, the functions start resolving and are popped off the stack one by one.
Expression Evaluation and Syntax Parsing
Another critical application of stacks is in evaluating mathematical expressions and parsing syntax in code compilers. Consider an arithmetic expression like 2 + 3 * 4. Before performing the operations, we need to check the precedence of the operators to get the correct result. Here, stacks come in handy to apply the BODMAS rule (Bracket, Order, Division and Multiplication, Addition and Subtraction).
Storing operators in a stack can help manage their execution order. Similar logic applies when compilers parse code syntax. They use stacks to check if all opening brackets have matching closing ones, which helps validate the syntax.
Undo Mechanism in Software Applications
Have you ever wondered how the ‘undo’ feature works in software applications like text editors, image editors, or even web browsers? Once again, stacks save the day. Each action you perform is pushed onto a stack. When you hit ‘undo’, the most recent action is popped from the stack and reversed. It’s a practical and elegant solution to a problem we encounter every day!
Backtracking Algorithms
Backtracking algorithms solve problems by trying out solutions and undoing them if they don’t lead to a solution. This is common in puzzles like Sudoku, the Eight Queens problem, and the Knight’s Tour problem.
In such scenarios, stacks are used to store the intermediate stages of the problem. When an attempted solution doesn’t work out, the algorithm can ‘pop’ back to a previous state and try a different path. It’s like having a ‘save game’ feature when you’re tackling a challenging puzzle!
Depth-First Search (DFS)
Stacks are also used in graph algorithms, specifically Depth-First Search (DFS). DFS explores a graph by visiting a node and recursively investigating all its unvisited neighbors. The algorithm uses a stack to remember which nodes to visit next when it finishes exploring a path.
By ‘pushing’ unvisited nodes onto the stack and ‘popping’ them once visited, DFS systematically explores every node in the graph. This method is particularly useful in network routing, AI behavior in games, and detecting cycles in a graph.
Web Page History in Browsers
Finally, an everyday example of stacks in action is web page history in a browser. When you click a link, your current page is ‘pushed’ onto a stack, and you’re taken to a new page. If you hit the ‘back’ button, your browser ‘pops’ the topmost page off the stack, taking you back to where you were. It’s a simple, intuitive way to navigate the vast expanse of the internet.
Conclusion
Through these examples, you can see just how versatile and vital stacks are in computer science and everyday applications.
Balanced Parentheses
Top Interview 150 | 20. Valid Parentheses Design Gurus
Problem Statement
Given a string s containing (, ), [, ], {, and } characters. Determine if a given string of parentheses is balanced.
A string of parentheses is considered balanced if every opening parenthesis has a corresponding closing parenthesis in the correct order.
Example 1:
Input: String s = “{[()]}”;
Expected Output: true
Explanation: The parentheses in this string are perfectly balanced. Every opening parenthesis ‘{‘, ‘[‘, ‘(‘ has a corresponding closing parenthesis ‘}’, ‘]’, ‘)’ in the correct order.
Example 2:
Input: string s = “{[}]”;
Expected Output: false
Explanation: The brackets are not balanced in this string. Although it contains the same number of opening and closing brackets for each type, they are not correctly ordered. The ‘]’ closes ‘[‘ before ‘{‘ can be closed by ‘}’, and similarly, ‘}’ closes ‘{‘ before ‘[‘ can be closed by ‘]’.
Example 3:
Input: String s = “(]”;
Expected Output: false
Explanation: The parentheses in this string are not balanced. Here, ‘)’ does not have a matching opening parenthesis ‘(‘, and similarly, ‘]’ does not have a matching opening bracket ‘[‘.
Constraints:
- 1 <= s.length <= 10^4
sconsists of parentheses only'()[]{}'.
Solution
To solve this problem, we use a stack data structure. As we traverse the string, each time we encounter an opening parenthesis (‘(‘, ‘{‘, or ‘[‘), we push it onto the stack. When we find a closing parenthesis (‘)’, ‘}’, or ‘]’), we check if it matches the type of the opening parenthesis at the top of the stack. If it matches, we pop the top element from the stack; if not, or if the stack is empty when we find a closing parenthesis, the string is not balanced, and we return false.
After processing the entire string, if the stack is empty, it means all parentheses were properly closed and nested, so we return true. Otherwise, we return false.
Here is a step-by-step algorithm:
- Initialize an empty Stack.
- Iterate over the string of parentheses.
- If the current character is an opening parenthesis, push it onto the Stack.
- If the current character is a closing parenthesis, check the top of the Stack.
- If the Stack is empty, then the string is not balanced (there is a closing parenthesis without a matching opening parenthesis), so return false.
- If the top of the Stack is the matching opening parenthesis, pop it off the Stack.
- If the top of the Stack is not the matching opening parenthesis, then the string is not balanced, so return false.
- After checking all parentheses, if the Stack is empty, then the string is balanced, so return true. If the Stack is not empty, then there are unmatched opening parentheses, so the string is not balanced, return false.
Algorithm Walkthrough
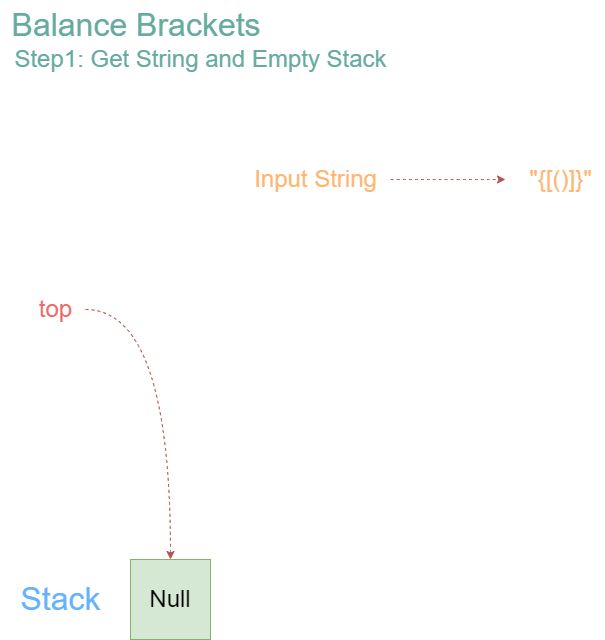
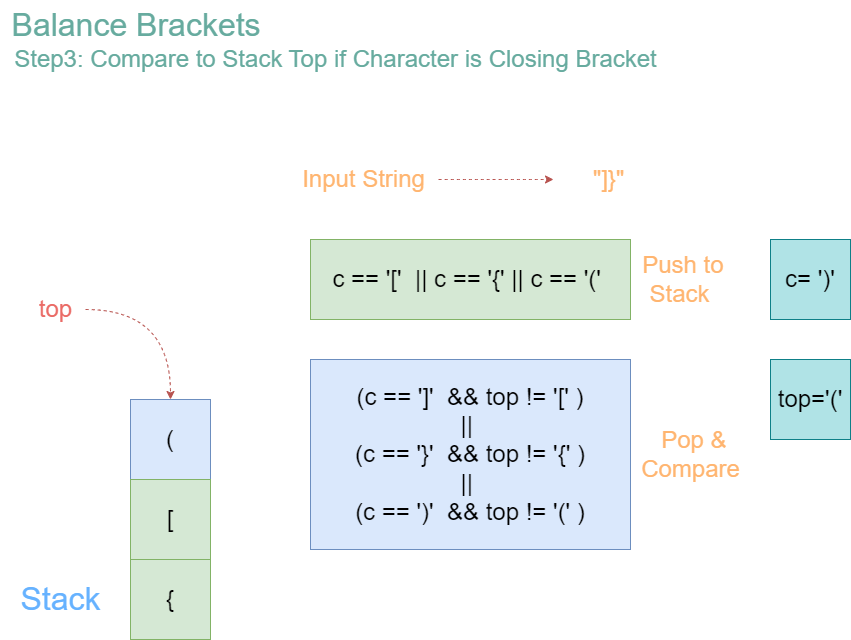
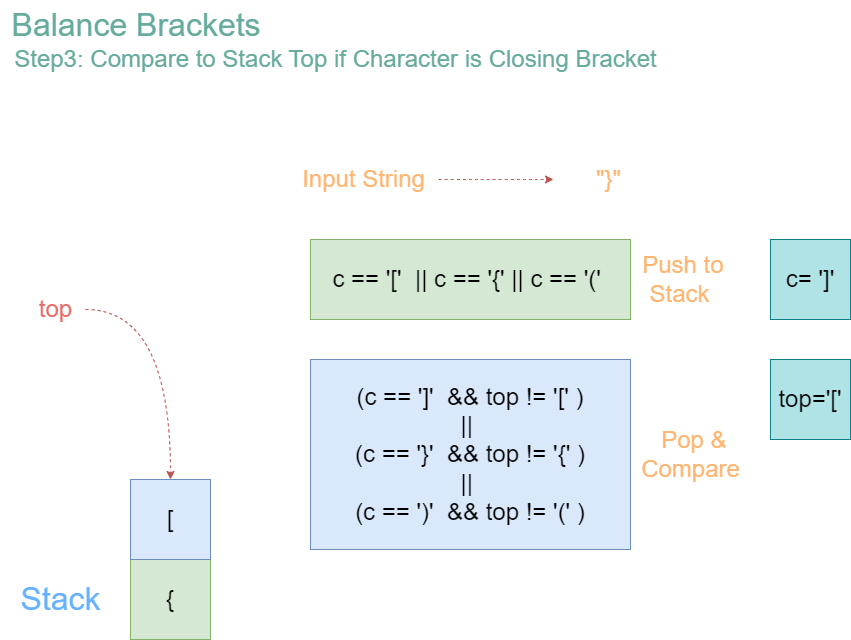
Let’s consider the input “{[()]}”, and observe how algorithm works.
Initialization:
- Start with an empty stack.
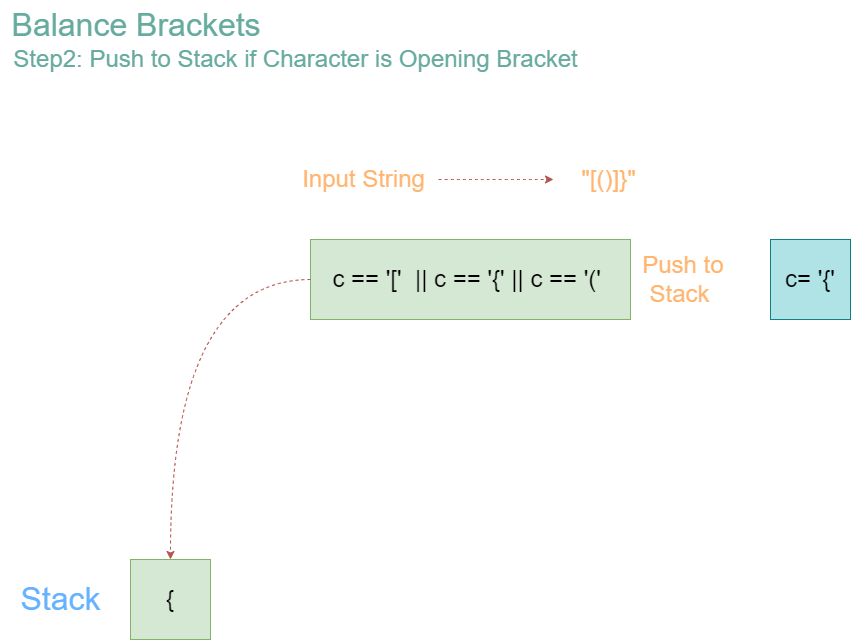
Iteration 1: Character = ‘{‘
- Stack before operation: []
- Since ‘{‘ is an opening bracket, push it onto the stack.
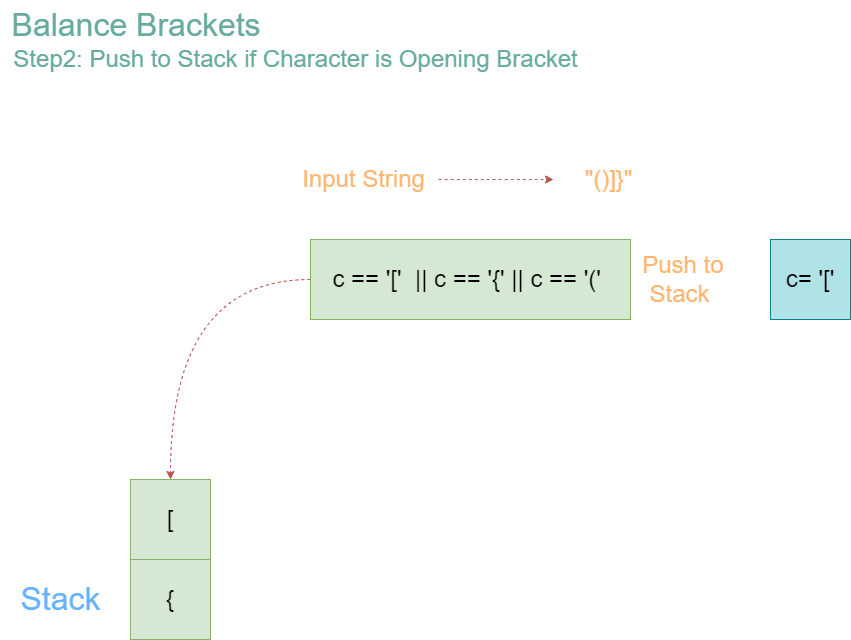
Iteration 2: Character = ‘[‘
- Stack before operation: [‘{‘]
- Since ‘[‘ is an opening bracket, push it onto the stack.
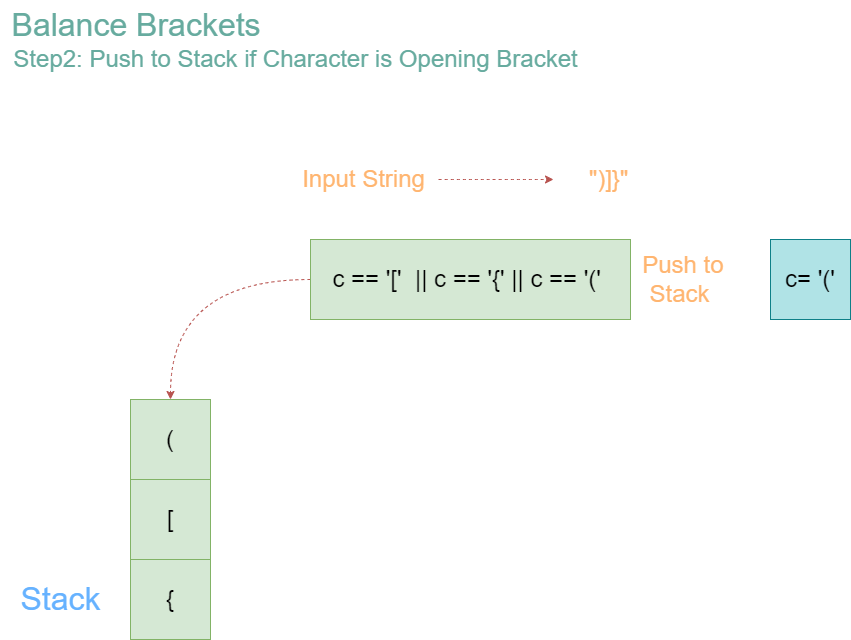
Iteration 3: Character = ‘(‘
- Stack before operation: [‘{‘, ‘[‘]
- Since ‘(‘ is an opening bracket, push it onto the stack.
Iteration 4: Character = ‘)’
- Stack before operation: [‘{‘, ‘[‘, ‘(‘]
- ‘)’ is a closing bracket. The top of the stack is ‘(‘, which is the corresponding opening bracket for ‘)’. So, pop ‘(‘ from the stack.
Iteration 5: Character = ‘]’
- Stack before operation: [‘{‘, ‘[‘]
- ‘]’ is a closing bracket. The top of the stack is ‘[‘, which is the corresponding opening bracket for ‘]’. So, pop ‘[‘ from the stack.
Iteration 6: Character = ‘}’
- Stack before operation: [‘{‘]
- ‘}’ is a closing bracket. The top of the stack is ‘{‘, which is the corresponding opening bracket for ‘}’. So, pop ‘{‘ from the stack.
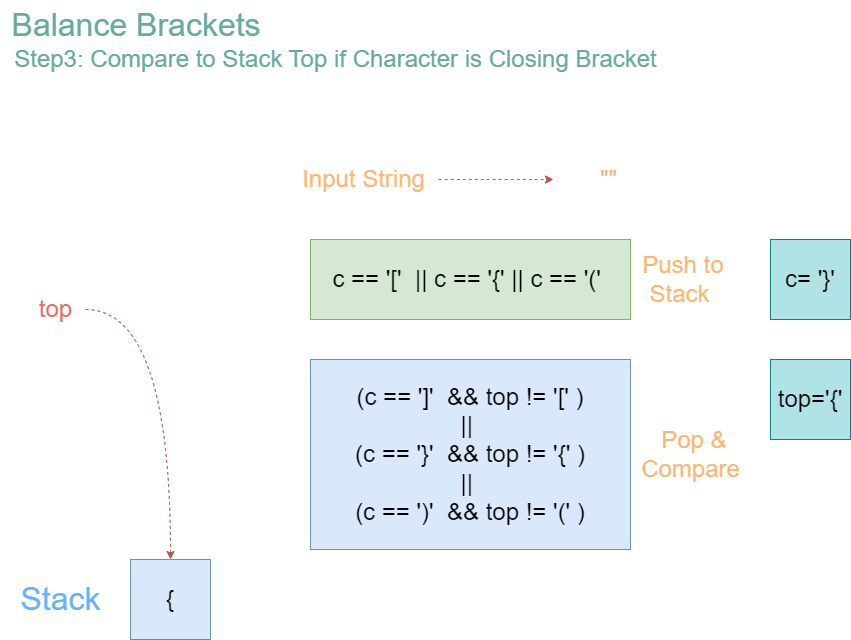
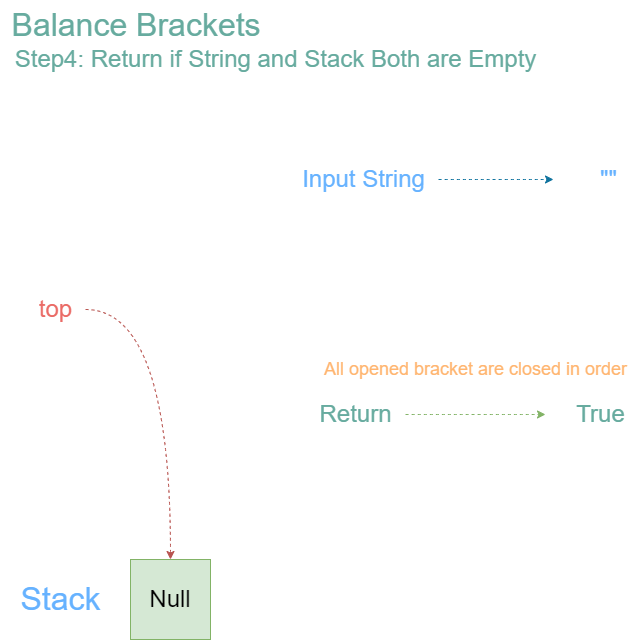
Final Check:
- After processing all characters, check the stack.
- The stack is empty, indicating that all opening brackets were properly matched and closed.
- Therefore, the input string “{[()]}” is valid with properly balanced parentheses.
Code
Here is how you can implement this algorithm:
1 | from collections import deque |
Time and Space Complexity Analysis
The time complexity of this algorithm is O(n), where n is the length of the string. This is because we’re processing each character in the string exactly once.
The space complexity is also O(n) in the worst-case scenario when all the characters in the string are opening parentheses, so we push each character onto the Stack. In the average case, however, the space complexity would be less than O(n).
Reverse a String
344. Reverse String Design Gurus
Problem Statement
Given a string, write a function that uses a stack to reverse the string. The function should return the reversed string.
Examples
Example 1:
1 | Input: "Hello, World!" |
Example 2:
1 | Input: "OpenAI" |
Example 3:
1 | Input: "Stacks are fun!" |
Constraints:
- 1 <= s.length <= 10^5
s[i]is a printable ascii character.
Solution
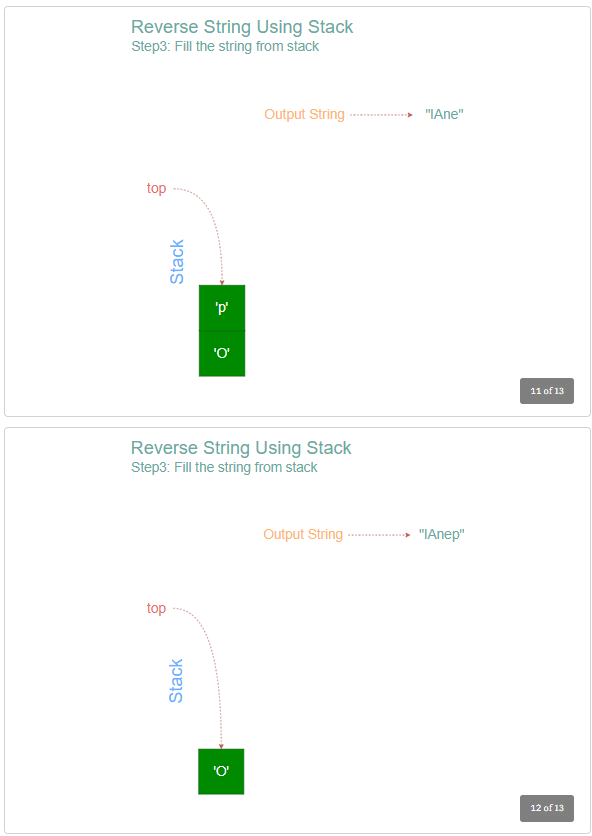
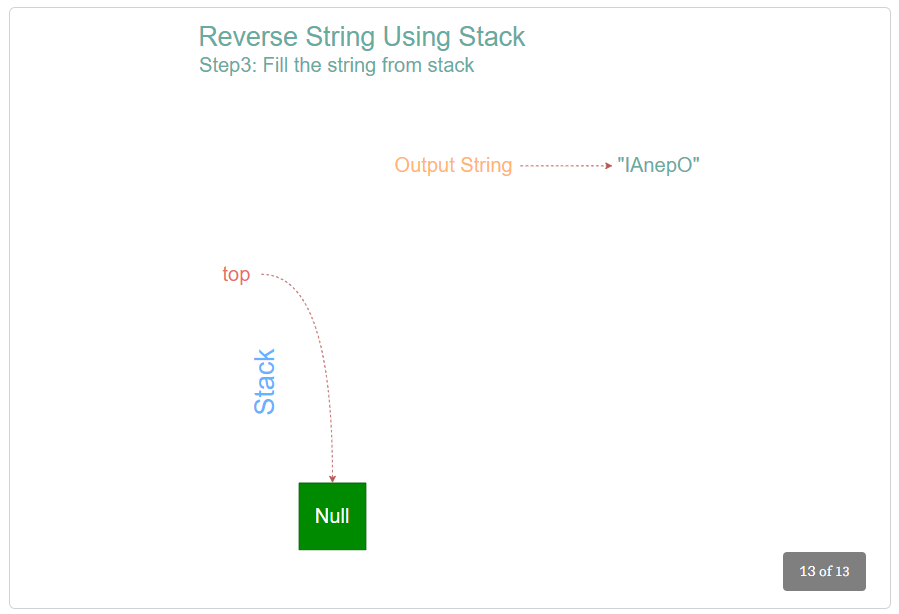
The solution to reverse a string can be elegantly achieved using a stack. The algorithm involves pushing each character of the string onto a stack and then popping them off, which naturally reverses their order. As we iterate through the string, each character is added to the top of the stack.
Once the entire string has been processed, we remove the characters from the stack one by one and append them to a new string. This process ensures that the characters are appended in reverse order, as the last character pushed onto the stack will be the first to be popped off. This method efficiently reverses the string while maintaining the integrity of the original data.
Here is the step-by-step algorithm.
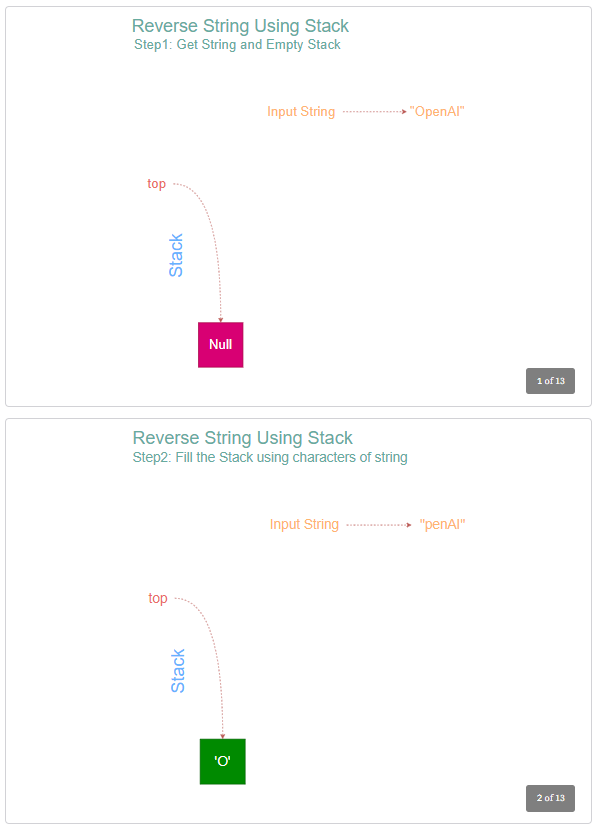
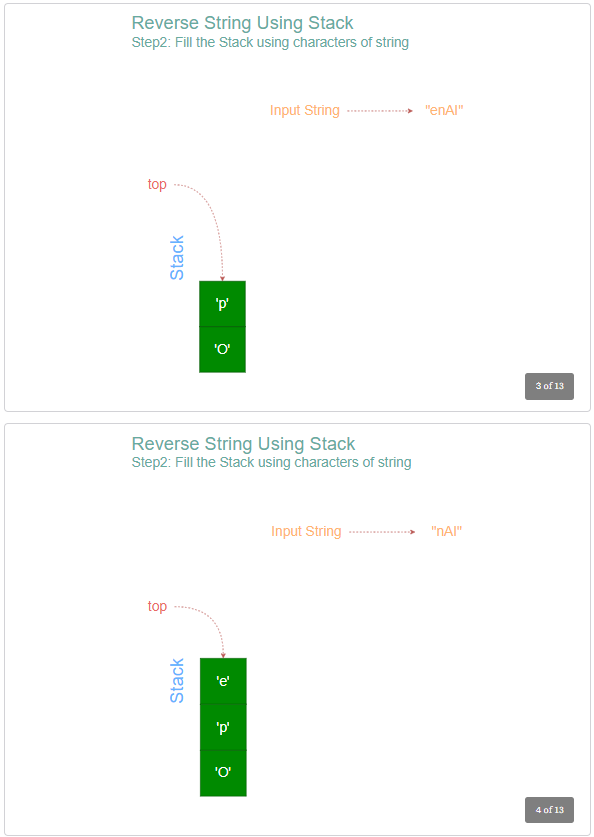
- Initialize an empty stack.
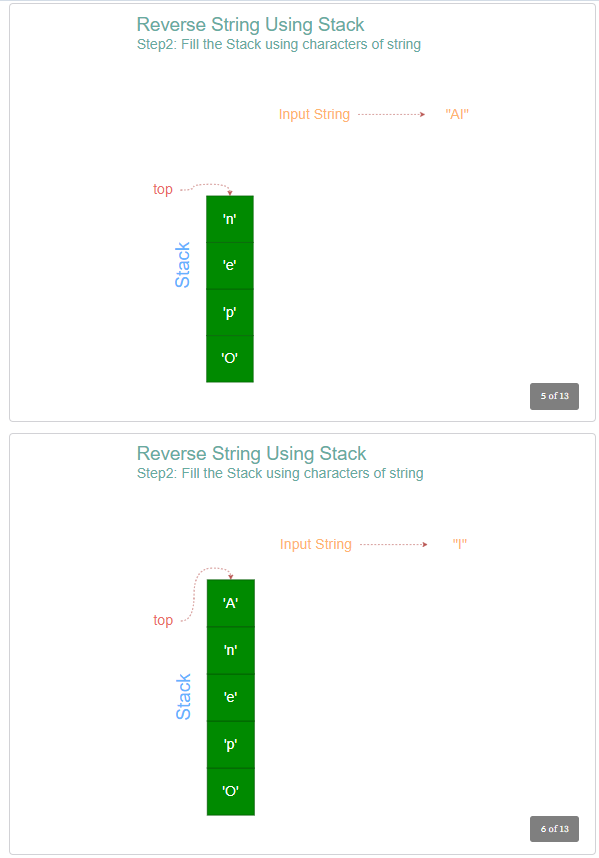
- For each character in the input string, push the character into the stack.
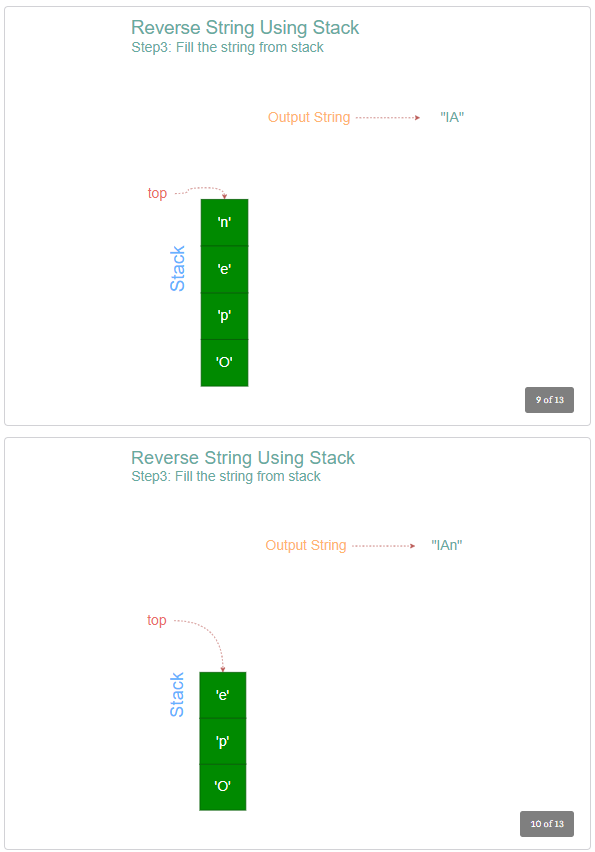
- Initialize an empty string to hold the reversed string.
- While the stack is not empty, pop out the top character from the stack and append it to the reversed string.
- Finally, return the reversed string.

Code
Here is how we can implement this algorithm:
1 | # Define a class named Solution |
Time and Space Complexity:
Time Complexity: O(n), where n is the length of the input string. This is because we iterate through the string once to push all characters into the stack and then another time to pop all characters out of the stack.
Space Complexity: O(n), where n is the length of the input string. This is because we use a stack to hold all characters of the string.
Decimal to Binary Conversion
Design Gurus
Problem Statement
Given a positive integer n, write a function that returns its binary equivalent as a string. The function should not use any in-built binary conversion function.
Examples
Example 1:
1 | Input: 2 |
Example 2:
1 | Input: 7 |
Example 3:
1 | Input: 18 |
Constraints:
- 0 <= num <= 10^9
Solution
We can use a stack to efficiently create the binary representation of a given decimal number. Our algorithm will take advantage of the ‘Last In, First Out’ property of stacks to reverse the order of the binary digits, since the binary representation is constructed from least significant bit to most significant bit, but needs to be displayed in the opposite order. The procedure involves repeatedly dividing the decimal number by 2, pushing the remainder onto the stack, which corresponds to the binary digit. When the number is reduced to 0, the algorithm pops elements off the stack and appends to the result string until the stack is empty, thereby reversing the order of digits. The result is the binary equivalent of the input decimal number.
Here is a detailed walkthrough of the solution:
- First, the algorithm starts by creating an empty stack. A stack is chosen because of its “Last In, First Out” property which is perfect for this type of problem where we need to reverse the order of the operations.
- Then, it enters into a loop where the given number is repeatedly divided by 2. This is because the binary number system is base 2, and each bit represents a power of 2.
- Inside the loop, the remainder when the number is divided by 2 (which is either 0 or 1) is pushed onto the stack. This remainder is essentially the bit in the binary representation of the number.
- The number is then updated by integer division by 2 (in programming languages, this is usually denoted by
num //= 2ornum = Math.floor(num / 2)ornum /= 2). This step essentially “shifts” the number one bit to the right. - Steps 3 and 4 are repeated until the number becomes zero.
- At this point, the stack contains the binary representation of the number, but in reverse order. This is because the first bit we calculated (the least significant bit, or the “rightmost” bit) is on the top of the stack, while the last bit we calculated (the most significant bit, or the “leftmost” bit) is on the bottom of the stack.
- So, the next step is to reverse this order. This is done by popping the stack until it’s empty and appending each popped bit to the result. Since a stack follows “Last In, First Out” rule, this will correctly reverse the order of the bits.
- Finally, the algorithm returns the result, which is the binary representation of the original number.
Code
Here is how we can implement this algorithm:
1 | from collections import deque |
Time and Space Complexity Analysis
The time complexity of this algorithm is O(log(n)) due to the division by 2 at each step.
The space complexity is also O(log(n)) because in each step we will be pushing an element on the stack, and there are a total of log(n) steps.
Next Greater Element
Design Gurus
Problem Statement
Given an array, print the Next Greater Element (NGE) for every element.
The Next Greater Element for an element x is the first greater element on the right side of x in the array.
Elements for which no greater element exist, consider the next greater element as -1.
Examples
Example 1:
1 | Input: |
Example 1:
1 | Input: |
Example 1:
1 | Input: [1, 2, 3, 4, 5] |
Constraints:
- 1 <= arr.length <= 10^4
- -109 <= arr[i] <= 10^9
Solution:
A simple algorithm is to run two loops: the outer loop picks all elements one by one, and the inner loop looks for the first greater element for the element picked by the outer loop. However, this algorithm has a time complexity of .
We can use a more optimized approach using Stack data structure. The algorithm will leverage the nature of the stack data structure, where the most recently added (pushed) elements are the first ones to be removed (popped). Starting from the end of the array, the algorithm always maintains elements in the stack that are larger than the current element. This way, it ensures that it has a candidate for the “next larger element”. If there is no larger element, it assigns -1 to that position. It handles each element of the array only once, making it an efficient solution.
Detailed Step-by-Step Walkthrough
- The function receives an array
arr. - Initialize an empty stack
sand an output arrayresof size equal to the input array, with all elements initialized to -1.reswill store the result, i.e., the next larger element for each position in the array. - Start a loop that goes from the last index of the array to the first (0 index).
- In each iteration, while there are elements in the stack and the top element of the stack is less than or equal to the current element in the array, remove elements from the stack. This step ensures that we retain only the elements in the stack that are larger than the current element.
- After the popping process, if there is still an element left in the stack, it is the next larger element for the current array element. So, assign the top element of the stack to the corresponding position in the
resarray. - Now, push the current array element into the stack. This action considers the current element as a possible “next larger element” for the upcoming elements in the remaining iterations.
- Repeat steps 4-6 for all the elements of the array.
- At the end of the loop,
reswill contain the next larger element for each position in the array. Return this arrayres.
Algorithm Walkthrough
Let’s consider the input and observe how above algorithm works.
- Initialize Data Structures:
- Input Array:
[13, 7, 6, 12] - Result Array:
[0, 0, 0, 0](Initially set to zeros) - Stack: Empty (Will store elements during iteration)
- Input Array:
- Processing Each Element (Reverse Order):
- The algorithm processes the array from right to left.
- Last Element (Value 12):
- Stack is empty, indicating no greater element for 12.
- Result Array:
[0, 0, 0, -1](Updates the last position to -1) - Push element 12 onto the stack.
- Third Element (Value 6):
- Stack’s top element is 12, which is greater than 6.
- Result Array:
[0, 0, 12, -1](Updates the value at the third position to 12) - Push element 6 onto the stack.
- Second Element (Value 7):
- Stack’s top element is 6, which is less than 7, so it’s popped.
- Next, the stack’s top element is 12, which is greater than 7.
- Result Array:
[0, 12, 12, -1](Updates the value at the second position to 12) - Push element 7 onto the stack.
- First Element (Value 13):
- Stack’s top element is 7, which is less than 13, so it’s popped.
- Next, stack’s top element is 12, which is also less than 13, so it’s popped.
- Stack is now empty, indicating no greater element for 13.
- Result Array:
[-1, 12, 12, -1](Updates the first position to -1) - Push element 13 onto the stack.
Here is the visual representation of the algorithm:



Code
Here is the code for this algorithm:
1 | from collections import deque |
Time and Space Complexity
Time Complexity: The worst-case time complexity of this algorithm is O(n) as every element is pushed and popped from the stack exactly once.
Space Complexity: The space complexity of this algorithm is O(n) as we are using a stack and an array to store the next greater elements.
Sorting a Stack
Design Gurus
Problem Statement
Given a stack, sort it using only stack operations (push and pop).
You can use an additional temporary stack, but you may not copy the elements into any other data structure (such as an array). The values in the stack are to be sorted in descending order, with the largest elements on top.
Examples
1 | 1. Input: [34, 3, 31, 98, 92, 23] |
Solution
This problem can be solved by using a temporary stack as auxiliary storage. The algorithm takes an input stack and sorts it using a temporary stack tmpStack. The sorting process is done by continuously popping elements from the input stack and pushing them onto the tmpStack in sorted order, rearranging elements as necessary between the stacks until the original stack is empty.
This algorithm leverages the LIFO (last in, first out) nature of a stack. It removes elements from the original stack one by one and uses a second stack to keep the elements sorted. If the top element of the sorted stack is larger than the current element, it moves the larger elements back to the original stack until it finds the correct spot for the current element, at which point it pushes the current element onto the sorted stack. Because of this, the smaller elements end up at the bottom of the sorted stack and the largest element on the top, resulting in a stack sorted in descending order from top to bottom.
Detailed Step-by-Step Walkthrough
- The
sortmethod receives an input stack. - It initializes an empty temporary stack
tmpStack. - The algorithm enters a loop that continues until the input stack is empty.
- In each iteration, it pops the top element (
tmp) from the input stack. - Then it enters another loop, which continues as long as
tmpStackis not empty and the top oftmpStackis larger thantmp. In each iteration of this inner loop, it pops the top element fromtmpStackand pushes it back onto the input stack. - After the inner loop ends, it pushes
tmpontotmpStack. The inner loop ensures thattmpStackis always sorted in descending order, with smaller elements at the bottom and larger elements at the top, andtmpis placed into its correct position in this order. - Once the outer loop ends and the input stack is empty,
tmpStackcontains all the elements originally in the input stack but sorted in descending order. - It then returns
tmpStack.
Algorithm Walkthrough
Initial Setup:
- Input Stack (top to bottom):
[34, 3, 31, 98, 92, 23] - Temporary Stack (
tmpStack): Empty
- Input Stack (top to bottom):
Process Element: 23
- Pop 23 from the input stack.
tmpStackis empty, so push 23 ontotmpStack.- Input Stack:
[34, 3, 31, 98, 92], tmpStack:[23]
Process Element: 92
- Pop 92 from the input stack.
- Since 23 < 92, push 92 onto
tmpStack. - Input Stack:
[34, 3, 31, 98], tmpStack:[23, 92]
Process Element: 98
- Pop 98 from the input stack.
- Since 92 < 98, push 98 onto
tmpStack. - Input Stack:
[34, 3, 31], tmpStack:[23, 92, 98]
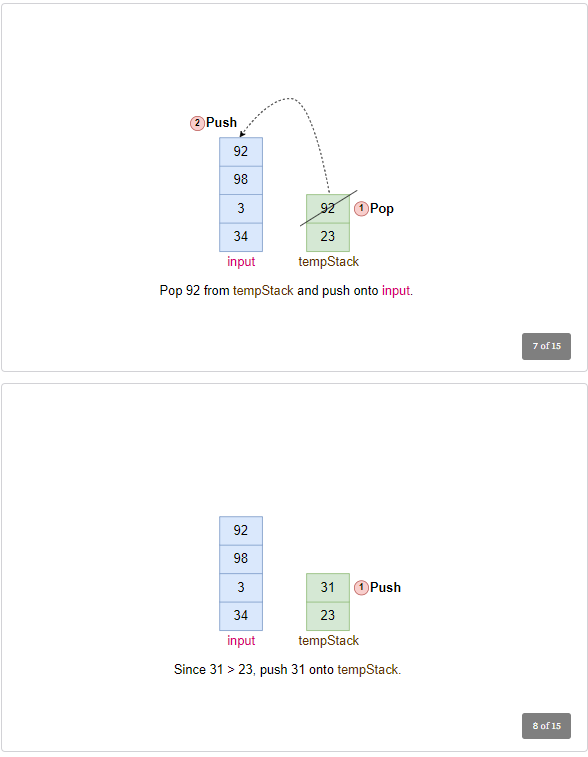
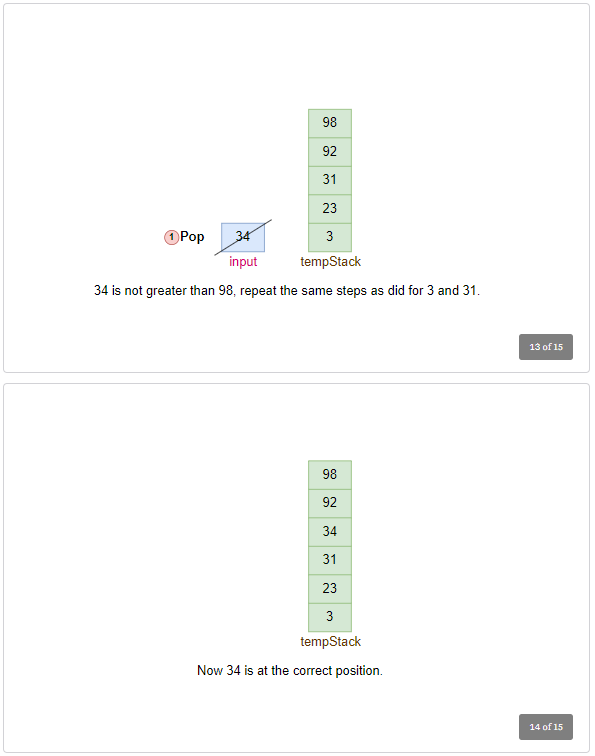
Process Element: 31
- Pop 31 from the input stack.
- Move elements from
tmpStackto input stack until the correct position for 31 is found. - Pop 98, then 92 from
tmpStackand push them onto the input stack. - Push 31 onto
tmpStack. - Input Stack:
[34, 3, 98, 92], tmpStack:[23, 31] - In next 2 iterations, pop 98, and 92 from
inputstack and push back to thetmpStack. Updated stack will be: Input Stack:[34, 3], tmpStack:[23, 31, 92, 98].
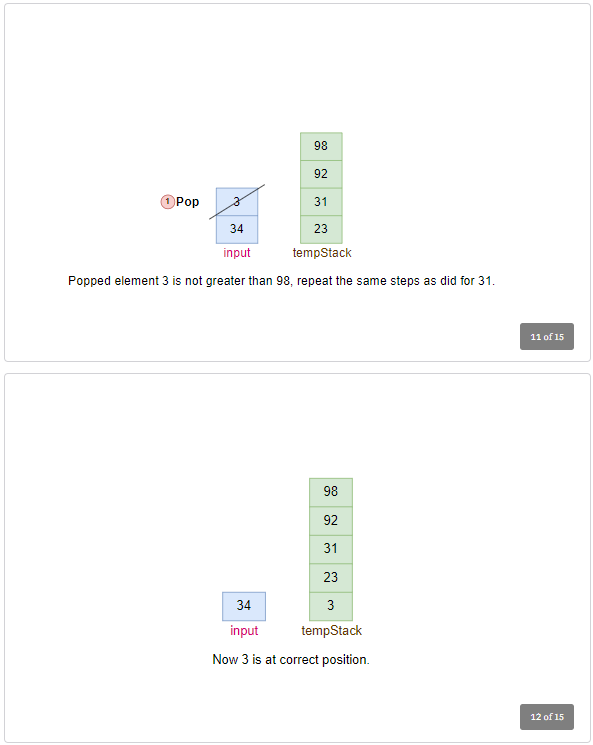
Process Element: 3
- Pop 3 from the input stack.
- Move elements from
tmpStackto input stack until the correct position for 3 is found.- Pop 98, 92, 31, then 23 from
tmpStackand push them onto the input stack.
- Pop 98, 92, 31, then 23 from
- Push 3 onto
tmpStack.- Input Stack:
[34, 98, 92, 31, 23], tmpStack:[3]- In next 4 iterations, pop 98, 92, 31, and 23 from the
inputstack and push back to thetmpStack. Updated stack will be: Input Stack:[34], tmpStack:[3, 23, 31, 92, 98].
- In next 4 iterations, pop 98, 92, 31, and 23 from the
- Input Stack:
Process Element: 34
- Pop 34 from the input stack.
- Move elements from
tmpStackto input stack until the correct position for 34 is found. - Pop 98, then 92 from
tmpStackand push them onto the input stack. - Push 34 onto
tmpStack. - Input Stack:
[98, 92], tmpStack:[3, 23, 31, 34]. - In next 2 iterations, pop 98, and 92 from the
inputstack and push to thetmpStack.
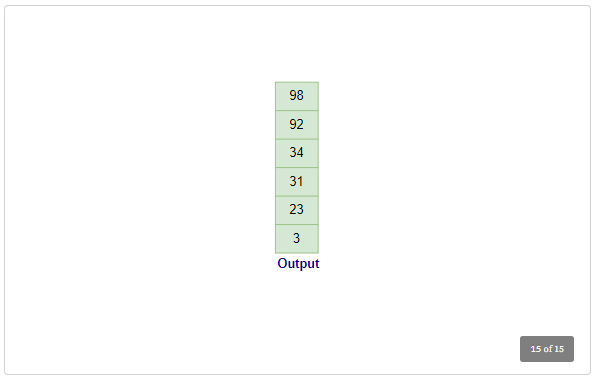
Final Result:
- Input Stack: Empty
- tmpStack (Sorted, top to bottom):
[3, 23, 31, 34, 92, 98]
Here is the visual representation of the algorithm:




Code
Here is the code for this algorithm:
1 | from collections import deque |
Time and Space Complexity
Time Complexity
The time complexity of the sort stack algorithm is O(n\^2) , where n is the number of elements in the stack. This is because, in the worst case, for every element that we pop from the input stack, we might have to pop all the elements in the temporary stack (and push them back to the original stack) to find the correct place to insert the element. Since we have to do this for all n elements, the time complexity is n n = n^2*.
Space Complexity
The space complexity of the algorithm is O(n). This is because we use an additional temporary stack to sort the elements. In the worst-case scenario, this temporary stack could store all the elements of the original stack. Thus, the space complexity is directly proportional to the number of elements in the input stack, making it linear, O(n).
Please note that the space complexity does not count the input size itself (the input stack in this case), it only counts the extra space we use related to the size of the input. If we were to count the input size as well, the total space used would be O(2n), but since we drop the constant factor when expressing space complexity, so it remains O(n).
Simplify Path
Top Interview 150 | 71. Simplify Path Design Gurus
Problem Statement
Given an absolute file path in a Unix-style file system, simplify it by converting “..” to the previous directory and removing any “.” or multiple slashes. The resulting string should represent the shortest absolute path.
Examples:
1 | 1. |
Constraints:
1 <= path.length <= 3000- path consists of English letters, digits, period ‘.’, slash ‘/‘ or ‘_’.
- path is a valid absolute Unix path.
Solution
To simplify the path, we’ll use a stack to track the directories we’re currently in. We’ll split the input path into components by the “/“ character, then process each component one by one. If a component is “..”, we go to the previous directory by popping the top of the stack. If a component is “.” or an empty string, we do nothing. Otherwise, we push the component into the stack as a new directory.
Detailed Algorithm steps:
- Split the input path by the “/“ character into an array of components.
- Initialize an empty stack.
- For each component in the array:
- If the component is “..”, pop the top of the stack (if it’s not already empty).
- Else if the component is “.” or an empty string, do nothing.
- Else, push the component into the stack as a new directory.
- Finally, combine the components in the stack into a string, separated by the “/“ character. Add a “/“ at the start to denote an absolute path.
Algorithm walkthrough
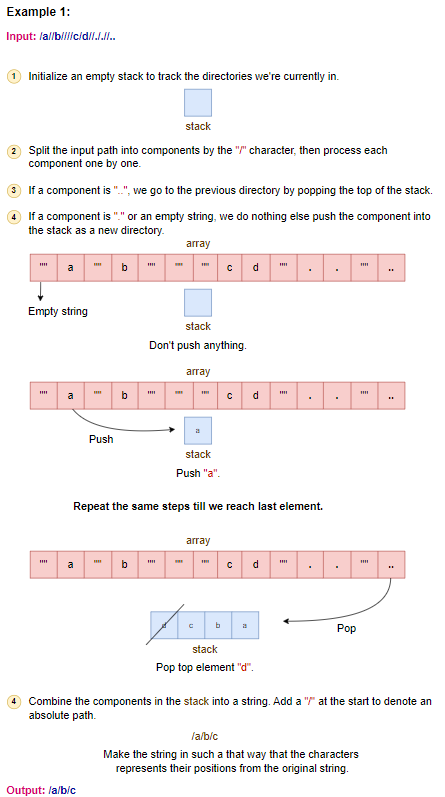
let’s walk through the code using the input "/a//b////c/d//././/.." step by step:
Initialize a Stack: A
Stack<String>is created to store components of the simplified path.Split the Path: The input path
"/a//b////c/d//././/.."is split using"/"as the delimiter. The resulting parts are:["", "a", "", "b", "", "", "", "c", "d", "", ".", "", ".", "", "", ".."]. Empty strings and dots (".") represent the current directory and will be ignored in further processing.Process Each Part:
- First Part (
""): It’s empty, so it’s ignored. - Second Part (
"a"): It’s a directory name and is pushed onto the stack. - Third Part (
""): Ignored. - Fourth Part (
"b"): Another directory name, pushed onto the stack. - Next Several Parts (
"","",""): All empty, so ignored. - Part
"c": A directory name, pushed onto the stack. - Part
"d": Another directory name, pushed onto the stack. - Part
".": Represents the current directory, ignored. - Part
"."(again): Again, represents the current directory, ignored. - Last Part (
".."): Represents moving up one directory. It pops"d"from the stack.
After processing, the stack contains:
["a", "b", "c"].- First Part (
Reconstruct Simplified Path:
- A
StringBuilderis used to construct the final simplified path. - The stack is processed in LIFO (Last-In-First-Out) order. Each component is popped and appended to the start of the result string, preceded by
"/". - After processing the stack, the
StringBuildercontains"/a/b/c".
- A
Return the Result:
- The
StringBuilderis converted to a string and returned. - For the given input, the output is
"/a/b/c".
- The
Here is the visual representation of the algorithm:
Code
Here is the code for this algorithm:
1 | from collections import deque |
Time and Space Complexity
The time complexity of the algorithm is O(n), where n is the size of the input path, since we process each character once. The space complexity is also O(n), as we store each directory in a stack.