
Introduction
In many problems dealing with an array (or a LinkedList), we are asked to find or calculate something among all the contiguous subarrays (or sublists) of a given size. For example, take a look at this problem:
Given an array, find the average of all contiguous subarrays of size ‘K’ in it.
Let’s understand this problem with a real input:
1 | Array: [1, 3, 2, 6, -1, 4, 1, 8, 2], K=5 |
Here, we are asked to find the average of all contiguous subarrays of size ‘5’ in the given array. Let’s solve this:
- For the first 5 numbers (subarray from index 0-4), the average is: (1+3+2+6-1)/5 => 2.2(1+3+2+6−1)/5=>2.2
- The average of next 5 numbers (subarray from index 1-5) is: (3+2+6-1+4)/5 => 2.8(3+2+6−1+4)/5=>2.8
- For the next 5 numbers (subarray from index 2-6), the average is: (2+6-1+4+1)/5 => 2.4(2+6−1+4+1)/5=>2.4
…
Here is the final output containing the averages of all contiguous subarrays of size 5:
1 | Output: [2.2, 2.8, 2.4, 3.6, 2.8] |
A brute-force algorithm will be to calculate the sum of every 5-element contiguous subarray of the given array and divide the sum by ‘5’ to find the average. This is what the algorithm will look like:
1 | class Solution: |
Time complexity: Since for every element of the input array, we are calculating the sum of its next ‘K’ elements, the time complexity of the above algorithm will be O(N\K)* where ‘N’ is the number of elements in the input array.
Can we find a better solution? Do you see any inefficiency in the above approach?
The inefficiency is that for any two consecutive subarrays of size ‘5’, the overlapping part (which will contain four elements) will be evaluated twice. For example, take the above-mentioned input:
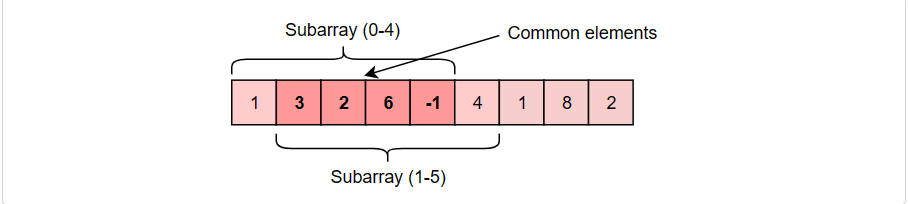
As you can see, there are four overlapping elements between the subarray (indexed from 0-4) and the subarray (indexed from 1-5). Can we somehow reuse the sum we have calculated for the overlapping elements?
The efficient way to solve this problem would be to visualize each contiguous subarray as a sliding window of ‘5’ elements. This means that when we move on to the next subarray, we will slide the window by one element. So, to reuse the sum from the previous subarray, we will subtract the element going out of the window and add the element now being included in the sliding window. This will save us from going through the whole subarray to find the sum and, as a result, the algorithm complexity will reduce to O(N).
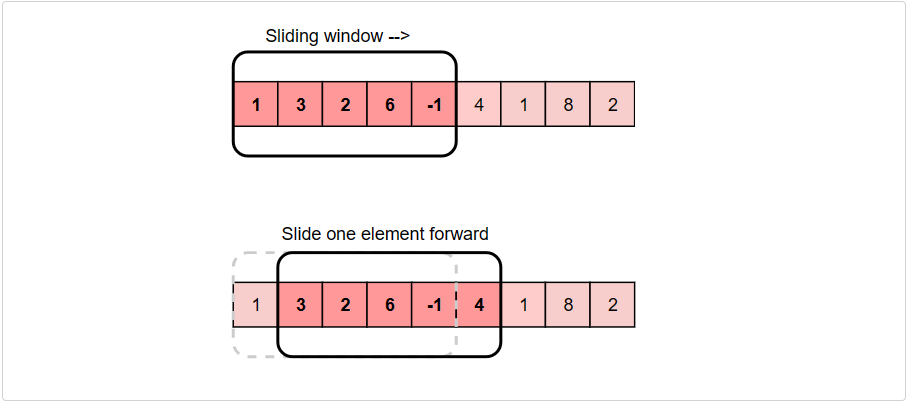
Here is the algorithm for the Sliding Window approach:
1 | class Solution: |
In the following chapters, we will apply the Sliding Window approach to solve a few problems.
In some problems, the size of the sliding window is not fixed. We have to expand or shrink the window based on the problem constraints. We will see a few examples of such problems in the next chapters.
Let’s jump onto our first problem and apply the Sliding Window pattern.
Maximum Sum Subarray of Size K (easy)
Design Gurus Educative.io
Problem Statement
Given an array of positive numbers and a positive number ‘k’, find the maximum sum of any contiguous subarray of size ‘k’.
Example 1:
1 | Input: [2, 1, 5, 1, 3, 2], k=3 |
Example 2:
1 | Input: [2, 3, 4, 1, 5], k=2 |
Solution
A basic brute force solution will be to calculate the sum of all ‘k’ sized subarrays of the given array to find the subarray with the highest sum. We can start from every index of the given array and add the next ‘k’ elements to find the subarray’s sum. Following is the visual representation of this algorithm for Example-1:
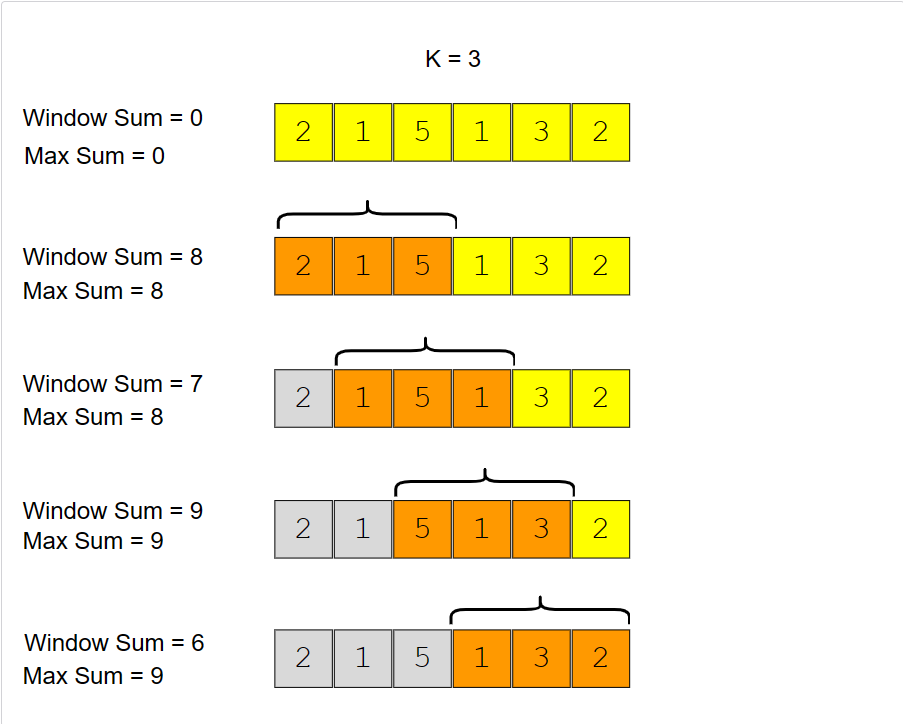
Code
Here is what our algorithm will look like:
1 | class Solution: |
Time Complexity
The time complexity of the above algorithm will be O(N).
Space Complexity
The algorithm runs in constant space O(1).
Smallest Subarray with a given sum (easy)
Top Interview 150 | 209. Minimum Size Subarray Sum Design Gurus Educative.io
Problem Statement
Given an array of positive numbers and a positive number ‘S’, find the length of the smallest contiguous subarray whose sum is greater than or equal to ‘S’. Return 0, if no such subarray exists.
Example 1:
1 | Input: [2, 1, 5, 2, 3, 2], S=7 |
Example 2:
1 | Input: [2, 1, 5, 2, 8], S=7 |
Example 3:
1 | Input: [3, 4, 1, 1, 6], S=8 |
Constraints:
- 1 <= S <= 10^9
- 1 <= arr.length <= 10^5
- 1 <= arr[i] <= 10^4
Solution
This problem follows the Sliding Window pattern and we can use a similar strategy as discussed in Maximum Sum Subarray of Size K. There is one difference though: in this problem, the size of the sliding window is not fixed. Here is how we will solve this problem:
- First, we will add-up elements from the beginning of the array until their sum becomes greater than or equal to ‘S’.
- These elements will constitute our sliding window. We are asked to find the smallest such window having a sum greater than or equal to ‘S’. We will remember the length of this window as the smallest window so far.
- After this, we will keep adding one element in the sliding window (i.e. slide the window ahead), in a stepwise fashion.
- In each step, we will also try to shrink the window from the beginning. We will shrink the window until the window’s sum is smaller than ‘S’ again. This is needed as we intend to find the smallest window. This shrinking will also happen in multiple steps; in each step we will do two things:
- Check if the current window length is the smallest so far, and if so, remember its length.
- Subtract the first element of the window from the running sum to shrink the sliding window.
Here is the visual representation of this algorithm for the Example-1:

Code
Here is what our algorithm will look:
1 | import math |
Time Complexity
The time complexity of the above algorithm will be O(N). The outer for loop runs for all elements and the inner while loop processes each element only once, therefore the time complexity of the algorithm will be O(N+N) which is asymptotically equivalent to O(N).
Space Complexity
The algorithm runs in constant space O(1).
Longest Substring with K Distinct Characters (medium)
Design Gurus Educative.io
Problem Statement
Given a string, find the length of the longest substring in it with no more than K distinct characters.
You can assume that K is less than or equal to the length of the given string.
Example 1:
1 | Input: String="araaci", K=2 |
Example 2:
1 | Input: String="araaci", K=1 |
Example 3:
1 | Input: String="cbbebi", K=3 |
Constraints:
- 1 <= str.length <= 5 * 104
0 <= K <= 50
Solution
This problem follows the Sliding Window pattern and we can use a similar dynamic sliding window strategy as discussed in Smallest Subarray with a given sum. We can use a HashMap to remember the frequency of each character we have processed. Here is how we will solve this problem:
- First, we will insert characters from the beginning of the string until we have ‘K’ distinct characters in the HashMap.
- These characters will constitute our sliding window. We are asked to find the longest such window having no more than ‘K’ distinct characters. We will remember the length of this window as the longest window so far.
- After this, we will keep adding one character in the sliding window (i.e. slide the window ahead), in a stepwise fashion.
- In each step, we will try to shrink the window from the beginning if the count of distinct characters in the HashMap is larger than ‘K’. We will shrink the window until we have no more than ‘K’ distinct characters in the HashMap. This is needed as we intend to find the longest window.
- While shrinking, we’ll decrement the frequency of the character going out of the window and remove it from the HashMap if its frequency becomes zero.
- At the end of each step, we’ll check if the current window length is the longest so far, and if so, remember its length.
Here is the visual representation of this algorithm for the Example-1:

Code
Here is how our algorithm will look:
1 | class Solution: |
Time Complexity
The time complexity of the above algorithm will be O(N) where ‘N’ is the number of characters in the input string. The outer for loop runs for all characters and the inner while loop processes each character only once, therefore the time complexity of the algorithm will be O(N+N)O(N+N) which is asymptotically equivalent to O(N).
Space Complexity
The space complexity of the algorithm is O(K), as we will be storing a maximum of ‘K+1’ characters in the HashMap.
Fruits into Baskets (medium)
904. Fruit Into Baskets Design Gurus Educative.io
You are visiting a farm to collect fruits. The farm has a single row of fruit trees. You will be given two baskets, and your goal is to pick as many fruits as possible to be placed in the given baskets.
You will be given an array of characters where each character represents a fruit tree. The farm has following restrictions:
- Each basket can have only one type of fruit. There is no limit to how many fruit a basket can hold.
- You can start with any tree, but you can’t skip a tree once you have started.
- You will pick exactly one fruit from every tree until you cannot, i.e., you will stop when you have to pick from a third fruit type.
Write a function to return the maximum number of fruits in both baskets.
Example 1:
1 | Input: arr=['A', 'B', 'C', 'A', 'C'] |
Example 2:
1 | Input: arr = ['A', 'B', 'C', 'B', 'B', 'C'] |
Constraints:
- 1 <= arr.length <= 10^5
0 <= arr[i] < arr.length
Solution
This problem follows the Sliding Window pattern and is quite similar to Longest Substring with K Distinct Characters. In this problem, we need to find the length of the longest subarray with no more than two distinct characters (or fruit types!). This transforms the current problem into Longest Substring with K Distinct Characters where K=2.
Code
Here is what our algorithm will look like, only the highlighted lines are different from Longest Substring with K Distinct Characters
1 | class Solution: |
Time Complexity
The time complexity of the above algorithm will be O(N) where ‘N’ is the number of characters in the input array. The outer for loop runs for all characters and the inner while loop processes each character only once, therefore the time complexity of the algorithm will be O(N+N)O(N+N) which is asymptotically equivalent to O(N).
Space Complexity
The algorithm runs in constant space O(1) as there can be a maximum of three types of fruits stored in the frequency map.
Similar Problems
Problem 1: Longest Substring with at most 2 distinct characters
Given a string, find the length of the longest substring in it with at most two distinct characters.
Solution: This problem is exactly similar to our parent problem.
No-repeat Substring (hard)
Top Interview 150 | 3. Longest Substring Without Repeating Characters Educative.io
Problem Statement
Given a string, find the length of the longest substring which has no repeating characters.
Example 1:
1 | Input: String="aabccbb" |
Example 2:
1 | Input: String="abbbb" |
Example 3:
1 | Input: String="abccde" |
Solution
This problem follows the Sliding Window pattern and we can use a similar dynamic sliding window strategy as discussed in Longest Substring with K Distinct Characters. We can use a HashMap to remember the last index of each character we have processed. Whenever we get a repeating character we will shrink our sliding window to ensure that we always have distinct characters in the sliding window.
Code
Here is what our algorithm will look like:
1 | def non_repeat_substring(str): |
Time Complexity
The time complexity of the above algorithm will be O(N) where ‘N’ is the number of characters in the input string.
Space Complexity
The space complexity of the algorithm will be O(K) where KK is the number of distinct characters in the input string. This also means K<=N, because in the worst case, the whole string might not have any repeating character so the entire string will be added to the HashMap. Having said that, since we can expect a fixed set of characters in the input string (e.g., 26 for English letters), we can say that the algorithm runs in fixed space O(1); in this case, we can use a fixed-size array instead of the HashMap.
*Longest Substring with Same Letters after Replacement (hard)
424. Longest Repeating Character Replacement Design Gurus Educative.io
Problem Statement
Given a string with lowercase letters only, if you are allowed to replace no more than ‘k’ letters with any letter, find the length of the longest substring having the same letters after replacement.
Example 1:
1 | Input: String="aabccbb", k=2 |
Example 2:
1 | Input: String="abbcb", k=1 |
Example 3:
1 | Input: String="abccde", k=1 |
Constraints:
- 1 <= str.length <= 10^5
sconsists of only lowercase English letters.0 <= k <= s.length
Solution
This problem follows the Sliding Window pattern, and we can use a similar dynamic sliding window strategy as discussed in Longest Substring with Distinct Characters. We can use a HashMap to count the frequency of each letter.
We will iterate through the string to add one letter at a time in the window.
We will also keep track of the count of the maximum repeating letter in any window (let’s call it
maxRepeatLetterCount).So, at any time, we know that we do have a window with one letter repeating
maxRepeatLetterCounttimes; this means we should try to replace the remaining letters.
- If the remaining letters are less than or equal to ‘k’, we can replace them all.
- If we have more than ‘k’ remaining letters, we should shrink the window as we cannot replace more than ‘k’ letters.
While shrinking the window, we don’t need to update maxRepeatLetterCount. Since we are only interested in the longest valid substring, our sliding windows do not have to shrink, even if a window may cover an invalid substring. Either we expand the window by appending a character to the right or we shift the entire window to the right by one. We only expand the window when the frequency of the newly added character exceeds the historical maximum frequency (from a previous window that included a valid substring). In other words, we do not need to know the exact maximum count of the current window. The only thing we need to know is whether the maximum count exceeds the historical maximum count, and that can only happen because of the newly added char.
Code
Here is what our algorithm will look like:
1 | class Solution: |
Time Complexity
The time complexity of the above algorithm will be O(N) where ‘N’ is the number of letters in the input string.
Space Complexity
As we are expecting only the lower case letters in the input string, we can conclude that the space complexity will be O(26), to store each letter’s frequency in the HashMap, which is asymptotically equal to O(1).
Longest Subarray with Ones after Replacement (hard)
1004. Max Consecutive Ones III Design Gurus Educative.io
Problem Statement
Given an array containing 0s and 1s, if you are allowed to replace no more than ‘k’ 0s with 1s, find the length of the longest contiguous subarray having all 1s.
Example 1:
1 | Input: Array=[0, 1, 1, 0, 0, 0, 1, 1, 0, 1, 1], k=2 |
Example 2:
1 | Input: Array=[0, 1, 0, 0, 1, 1, 0, 1, 1, 0, 0, 1, 1], k=3 |
Constraints:
- 1 <= arr.length <= 10^5
arr[i]is either 0 or 1.0 <= k <= nums.length
Solution
This problem follows the Sliding Window pattern and is quite similar to Longest Substring with same Letters after Replacement. The only difference is that, in the problem, we only have two characters (1s and 0s) in the input arrays.
Following a similar approach, we’ll iterate through the array to add one number at a time in the window. We’ll also keep track of the maximum number of repeating 1s in the current window (let’s call it maxOnesCount). So at any time, we know that we can have a window with 1s repeating maxOnesCount time, so we should try to replace the remaining 0s. If we have more than ‘k’ remaining 0s, we should shrink the window as we are not allowed to replace more than ‘k’ 0s.
Code
Here is how our algorithm will look like:
1 | class Solution: |
Time Complexity
The time complexity of the above algorithm will be O(N) where ‘N’ is the count of numbers in the input array.
Space Complexity
The algorithm runs in constant space O(1).
*Problem Challenge 1
567. Permutation in String Design Gurus Educative.io
Permutation in a String (hard)
Given a string and a pattern, find out if the string contains any permutation of the pattern.
Permutation is defined as the re-arranging of the characters of the string. For example, “abc” has the following six permutations:
- abc
- acb
- bac
- bca
- cab
- cba
If a string has ‘n’ distinct characters it will have n! permutations.
Example 1:
1 | Input: String="oidbcaf", Pattern="abc" |
Example 2:
1 | Input: String="odicf", Pattern="dc" |
Example 3:
1 | Input: String="bcdxabcdy", Pattern="bcdyabcdx" |
Example 4:
1 | Input: String="aaacb", Pattern="abc" |
Constraints:
- 1 <= str.length, pat.length <= 104
strandpatconsist of lowercase English letters.
Solution
This problem follows the Sliding Window pattern and we can use a similar sliding window strategy as discussed in Longest Substring with K Distinct Characters. We can use a HashMap to remember the frequencies of all characters in the given pattern. Our goal will be to match all the characters from this HashMap with a sliding window in the given string. Here are the steps of our algorithm:
- Create a HashMap to calculate the frequencies of all characters in the pattern.
- Iterate through the string, adding one character at a time in the sliding window.
- If the character being added matches a character in the HashMap, decrement its frequency in the map. If the character frequency becomes zero, we got a complete match.
- If at any time, the number of characters matched is equal to the number of distinct characters in the pattern (i.e., total characters in the HashMap), we have gotten our required permutation.
- If the window size is greater than the length of the pattern, shrink the window to make it equal to the size of the pattern. At the same time, if the character going out was part of the pattern, put it back in the frequency HashMap.
Code
Here is what our algorithm will look like:
1 | class Solution: |
Time Complexity
The time complexity of the above algorithm will be O(N + M) where ‘N’ and ‘M’ are the number of characters in the input string and the pattern respectively.
Space Complexity
The space complexity of the algorithm is O(M) since in the worst case, the whole pattern can have distinct characters which will go into the HashMap.
Problem Challenge 2
438. Find All Anagrams in a String Design Gurus Educative.io
String Anagrams (hard)
Given a string and a pattern, find all anagrams of the pattern in the given string.
Anagram is actually a Permutation of a string. For example, “abc” has the following six anagrams:
- abc
- acb
- bac
- bca
- cab
- cba
Write a function to return a list of starting indices of the anagrams of the pattern in the given string.
Example 1:
1 | Input: String="ppqp", Pattern="pq" |
Example 2:
1 | Input: String="abbcabc", Pattern="abc" |
Constraints:
- 1 <= s.length, p.length <= 3 * 10^4
strandpatternconsist of lowercase English letters.
Solution
This problem follows the Sliding Window pattern and is very similar to Permutation in a String. In this problem, we need to find every occurrence of any permutation of the pattern in the string. We will use a list to store the starting indices of the anagrams of the pattern in the string.
Code
Here is what our algorithm will look like, only the highlighted lines have changed from Permutation in a String:
1 | class Solution: |
Time Complexity
The time complexity of the above algorithm will be O(N + M) where ‘N’ and ‘M’ are the number of characters in the input string and the pattern respectively.
Space Complexity
The space complexity of the algorithm is O(M) since in the worst case, the whole pattern can have distinct characters which will go into the HashMap. In the worst case, we also need O(N) space for the result list, this will happen when the pattern has only one character and the string contains only that character.
Problem Challenge 3
Top Interview 150 | 76. Minimum Window Substring Design Gurus Educative.io
Smallest Window containing Substring (hard)
Given a string and a pattern, find the smallest substring in the given string which has all the characters of the given pattern.
Example 1:
1 | Input: String="aabdec", Pattern="abc" |
Example 2:
1 | Input: String="aabdec", Pattern="abac" |
Example 3:
1 | Input: String="abdbca", Pattern="abc" |
Example 4:
1 | Input: String="adcad", Pattern="abc" |
Constraints:
- m == String.length
- n == Pattern.length
- 1 <= m, n <= 10^5
StringandPatternconsist of uppercase and lowercase English letters.
Solution
This problem follows the Sliding Window pattern and has a lot of similarities with Permutation in a String with one difference. In this problem, we need to find a substring having all characters of the pattern which means that the required substring can have some additional characters and doesn’t need to be a permutation of the pattern. Here is how we will manage these differences:
- We will keep a running count of every matching instance of a character.
- Whenever we have matched all the characters, we will try to shrink the window from the beginning, keeping track of the smallest substring that has all the matching characters.
- We will stop the shrinking process as soon as we remove a matched character from the sliding window. One thing to note here is that we could have redundant matching characters, e.g., we might have two ‘a’ in the sliding window when we only need one ‘a’. In that case, when we encounter the first ‘a’, we will simply shrink the window without decrementing the matched count. We will decrement the matched count when the second ‘a’ goes out of the window.
Code
Here is how our algorithm will look; only the highlighted lines have changed from Permutation in a String:
1 | class Solution: |
Time Complexity
The time complexity of the above algorithm will be O(N + M) where ‘N’ and ‘M’ are the number of characters in the input string and the pattern respectively.
Space Complexity
The space complexity of the algorithm is O(M) since in the worst case, the whole pattern can have distinct characters which will go into the HashMap. In the worst case, we also need O(N) space for the resulting substring, which will happen when the input string is a permutation of the pattern.
*Problem Challenge 4
Top Interview 150 | 30. Substring with Concatenation of All Words Design Gurus Educative.io
Words Concatenation (hard)
Given a string and a list of words, find all the starting indices of substrings in the given string that are a concatenation of all the given words exactly once without any overlapping of words. It is given that all words are of the same length.
Example 1:
1 | Input: String="catfoxcat", Words=["cat", "fox"] |
Example 2:
1 | Input: String="catcatfoxfox", Words=["cat", "fox"] |
Constraints:
- 1 <= words.length <= 10^4
1 <= words[i].length <= 30words[i]consists of only lowercase English letters.- All the strings of words are
unique. - 1 <= sum(words[i].length) <= 10^5
Solution
This problem follows the Sliding Window pattern and has a lot of similarities with Maximum Sum Subarray of Size K. We will keep track of all the words in a HashMap and try to match them in the given string. Here are the set of steps for our algorithm:
- Keep the frequency of every word in a HashMap.
- Starting from every index in the string, try to match all the words.
- In each iteration, keep track of all the words that we have already seen in another HashMap.
- If a word is not found or has a higher frequency than required, we can move on to the next character in the string.
- Store the index if we have found all the words.
Code
Here is what our algorithm will look like:
1 | class Solution: |
Time Complexity
The time complexity of the above algorithm will be O(N M Len) where ‘N’ is the number of characters in the given string, ‘M’ is the total number of words, and ‘Len’ is the length of a word.
Space Complexity
The space complexity of the algorithm is O(M) since at most, we will be storing all the words in the two HashMaps. In the worst case, we also need O(N) space for the resulting list. So, the overall space complexity of the algorithm will be O(M+N).