
Introduction
Any problem that asks us to find the top/smallest/frequent ‘K’ elements among a given set falls under this pattern.
The best data structure that comes to mind to keep track of ‘K’ elements is Heap). This pattern will make use of the Heap to solve multiple problems dealing with ‘K’ elements at a time from a set of given elements.
Let’s jump onto our first problem to develop an understanding of this pattern.
1 | 做这种pattern的题目有三种方式 |
Top ‘K’ Numbers (easy)
Design Gurus Educative.io
Problem Statement
Given an unsorted array of numbers, find the ‘K’ largest numbers in it.
Note: For a detailed discussion about different approaches to solve this problem, take a look at Kth Smallest Number(这是Miscellaneous类别的)
Example 1:
1 | Input: [3, 1, 5, 12, 2, 11], K = 3 |
Example 2:
1 | Input: [5, 12, 11, -1, 12], K = 3 |
Constraints:
- 1 <= nums.length <= 10^5
- -10^5 <= nums[i] <= 10^5
- k is in the range [1, the number of unique elements in the array].
- It is guaranteed that the answer is unique.
Solution
A brute force solution could be to sort the array and return the largest K numbers. The time complexity of such an algorithm will be O(N\logN)* as we need to use a sorting algorithm like Timsort if we use Java’s Collection.sort(). Can we do better than that?
The best data structure that comes to mind to keep track of top ‘K’ elements is Heap). Let’s see if we can use a heap to find a better algorithm.
If we iterate through the array one element at a time and keep ‘K’ largest numbers in a heap such that each time we find a larger number than the smallest number in the heap, we do two things:
- Take out the smallest number from the heap, and
- Insert the larger number into the heap.
This will ensure that we always have ‘K’ largest numbers in the heap. The most efficient way to repeatedly find the smallest number among a set of numbers will be to use a min-heap. As we know, we can find the smallest number in a min-heap in constant time O(1), since the smallest number is always at the root of the heap. Extracting the smallest number from a min-heap will take O(logN) (if the heap has ‘N’ elements) as the heap needs to readjust after the removal of an element.
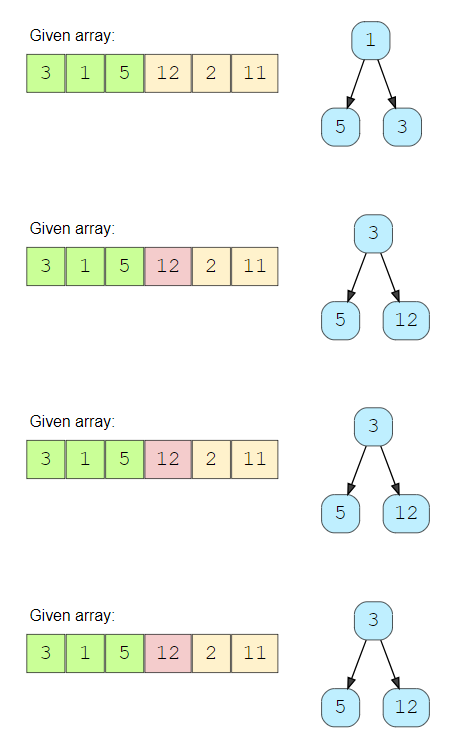
Let’s take Example-1 to go through each step of our algorithm:
Given array: [3, 1, 5, 12, 2, 11], and K=3
- First, let’s insert ‘K’ elements in the min-heap.
- After the insertion, the heap will have three numbers [3, 1, 5] with ‘1’ being the root as it is the smallest element.
- We’ll iterate through the remaining numbers and perform the above-mentioned two steps if we find a number larger than the root of the heap.
- The 4th number is ‘12’ which is larger than the root (which is ‘1’), so let’s take out ‘1’ and insert ‘12’. Now the heap will have [3, 5, 12] with ‘3’ being the root as it is the smallest element.
- The 5th number is ‘2’ which is not bigger than the root of the heap (‘3’), so we can skip this as we already have top three numbers in the heap.
- The last number is ‘11’ which is bigger than the root (which is ‘3’), so let’s take out ‘3’ and insert ‘11’. Finally, the heap has the largest three numbers: [5, 12, 11]
As discussed above, it will take us O(logK) to extract the minimum number from the min-heap. So the overall time complexity of our algorithm will be O(K\logK+(N-K)*logK)* since, first, we insert ‘K’ numbers in the heap and then iterate through the remaining numbers and at every step, in the worst case, we need to extract the minimum number and insert a new number in the heap. This algorithm is better than O(N\logN)*.
Here is the visual representation of our algorithm:
1 | from heapq import * |
Time complexity
As discussed above, the time complexity of this algorithm is O(KlogK+(N-K)logK), which is asymptotically equal to O(NlogK)
Space complexity
The space complexity will be O(K) since we need to store the top ‘K’ numbers in the heap.
Kth Smallest Number (easy)
Top Interview 150 | 215. Kth Largest Element in an Array Design Gurus Educative.io
Problem Statement
Given an unsorted array of numbers, find Kth smallest number in it.
Please note that it is the Kth smallest number in the sorted order, not the Kth distinct element.
Note: For a detailed discussion about different approaches to solve this problem, take a look at Kth Smallest Number.
Example 1:
1 | Input: [1, 5, 12, 2, 11, 5], K = 3 |
Example 2:
1 | Input: [1, 5, 12, 2, 11, 5], K = 4 |
Example 3:
1 | Input: [5, 12, 11, -1, 12], K = 3 |
Constraints:
- 1 <= k <= nums.length <= 10^5
- -10^4 <= nums[i] <= 10^4
Solution
This problem follows the Top ‘K’ Numbers pattern but has two differences:
- Here we need to find the Kth
smallestnumber, whereas in Top ‘K’ Numbers we were dealing with ‘K’largestnumbers. - In this problem, we need to find only one number (Kth smallest) compared to finding all ‘K’ largest numbers.
We can follow the same approach as discussed in the ‘Top K Elements’ problem. To handle the first difference mentioned above, we can use a max-heap instead of a min-heap. As we know, the root is the biggest element in the max heap. So, since we want to keep track of the ‘K’ smallest numbers, we can compare every number with the root while iterating through all numbers, and if it is smaller than the root, we’ll take the root out and insert the smaller number.
Code
Here is what our algorithm will look like:
1 | from heapq import * |
Time complexity
The time complexity of this algorithm is O(KlogK+(N-K)logK), which is asymptotically equal to O(N\logK)*
Space complexity
The space complexity will be O(K) because we need to store ‘K’ smallest numbers in the heap.
An Alternate Approach
Alternatively, we can use a Min Heap to find the Kth smallest number. We can insert all the numbers in the min-heap and then extract the top ‘K’ numbers from the heap to find the Kth smallest number. Initializing the min-heap with all numbers will take O(N) and extracting ‘K’ numbers will take O(KlogN). Overall, the time complexity of this algorithm will be O(N+KlogN) and the space complexity will be O(N).
‘K’ Closest Points to the Origin (easy)
973. K Closest Points to Origin Design Gurus Educative.io
Problem Statement
Given an array of points in the a 2D plane, find ‘K’ closest points to the origin.
Example 1:
1 | Input: points = [[1,2],[1,3]], K = 1 |
Example 2:
1 | Input: point = [[1, 3], [3, 4], [2, -1]], K = 2 |
Constraints:
- 1 <= k <= points.length <= 10^4
- -10^4 <= xi, yi <= 10^4
Solution
The Euclidean distance of a point P(x,y) from the origin can be calculated through the following formula:
\sqrt{x^2 + y^2}√x2+y2
This problem follows the Top ‘K’ Numbers pattern. The only difference in this problem is that we need to find the closest point (to the origin) as compared to finding the largest numbers.
Following a similar approach, we can use a Max Heap to find ‘K’ points closest to the origin. While iterating through all points, if a point (say ‘P’) is closer to the origin than the top point of the max-heap, we will remove that top point from the heap and add ‘P’ to always keep the closest points in the heap.
Code
Here is what our algorithm will look like:
1 | # 如果要构造kth closest的point,也是构造大顶堆,只不过返回的时候返回第一个就可以 |
Time complexity
The time complexity of this algorithm is (N\logK)* as we iterating all points and pushing them into the heap.
Space complexity
The space complexity will be O(K) because we need to store ‘K’ point in the heap.
Connect Ropes (easy)
Leetcode 1167 会员 Design Gurus Educative.io
Problem Statement
Given ‘N’ ropes with different lengths, we need to connect these ropes into one big rope with minimum cost. The cost of connecting two ropes is equal to the sum of their lengths.
Example 1:
1 | Input: |
Example 2:
1 | Input: |
Example 3:
1 | Input: |
Constraints:
- 1 <= ropLengths.length <= 10^4
- 1 <= ropLengths[i] <= 10^4
Solution
In this problem, following a greedy approach to connect the smallest ropes first will ensure the lowest cost. We can use a Min Heap to find the smallest ropes following a similar approach as discussed in Kth Smallest Number. Once we connect two ropes, we need to insert the resultant rope back in the Min Heap so that we can connect it with the remaining ropes.
Code
Here is what our algorithm will look like:
1 | from heapq import * |
Time complexity
Given ‘N’ ropes, we need O(N\logN)* to insert all the ropes in the heap. In each step, while processing the heap, we take out two elements from the heap and insert one. This means we will have a total of ‘N’ steps, having a total time complexity of O(N\logN)*.
Space complexity
The space complexity will be O(N) because we need to store all the ropes in the heap.
Top ‘K’ Frequent Numbers (medium)
347. Top K Frequent Elements Design Gurus Educative.io
Problem Statement
Given an unsorted array of numbers, find the top ‘K’ frequently occurring numbers in it.
Example 1:
1 | Input: [1, 3, 5, 12, 11, 12, 11], K = 2 |
Example 2:
1 | Input: [5, 12, 11, 3, 11], K = 2 |
Constraints:
- 1 <= nums.length <= 10^5
- -10^5 <= nums[i] <= 10^5
- k is in the range [1, the number of unique elements in the array].
- It is guaranteed that the answer is unique.
Solution
This problem follows Top ‘K’ Numbers. The only difference is that in this problem, we need to find the most frequently occurring number compared to finding the largest numbers.
We can follow the same approach as discussed in the Top K Elements problem. However, in this problem, we first need to know the frequency of each number, for which we can use a HashMap. Once we have the frequency map, we can use a Min Heap to find the ‘K’ most frequently occurring number. In the Min Heap, instead of comparing numbers we will compare their frequencies in order to get frequently occurring numbers
Code
Here is what our algorithm will look like:
1 | from heapq import * |
Time complexity
The time complexity of the above algorithm is O(N+N\logK)*.
Space complexity
The space complexity will be O(N). Even though we are storing only ‘K’ numbers in the heap. For the frequency map, however, we need to store all the ‘N’ numbers.
Frequency Sort (medium)
451. Sort Characters By Frequency Design Gurus Educative.io
Problem Statement
Given a string, sort it based on the decreasing frequency of its characters.
Example 1:
1 | Input: "Programming" |
Example 2:
1 | Input: "abcbab" |
Constraints:
- 1 <= str.length <= 5 * 10^5
- str consists of uppercase and lowercase English letters and digits.
Solution
This problem follows the Top ‘K’ Elements pattern, and shares similarities with Top ‘K’ Frequent Numbers.
We can follow the same approach as discussed in the Top ‘K’ Frequent Numbers problem. First, we will find the frequencies of all characters, then use a max-heap to find the most occurring characters.
Code
Here is what our algorithm will look like:
1 | from heapq import * |
Time complexity
The time complexity of the above algorithm is O(D\logD)* where ‘D’ is the number of distinct characters in the input string. This means, in the worst case, when all characters are unique the time complexity of the algorithm will be O(N\logN)* where ‘N’ is the total number of characters in the string.
Space complexity
The space complexity will be O(N), as in the worst case, we need to store all the ‘N’ characters in the HashMap.
Kth Largest Number in a Stream (medium)
leetcode 703 一样的代码,leetcode报错,感觉是leetcode内部问题
703. Kth Largest Element in a Stream Design Gurus Educative.io
Problem Statement
Design a class to efficiently find the Kth largest element in a stream of numbers.
The class should have the following two things:
- The constructor of the class should accept an integer array containing initial numbers from the stream and an integer ‘K’.
- The class should expose a function
add(int num)which will store the given number and return the Kth largest number.
Example 1:
1 | Input: [3, 1, 5, 12, 2, 11], K = 4 |
Constraints:
- 1 <= k <= 10^4
- 0 <= nums.length <= 10^4
- -10^4 <= nums[i] <= 10^4
- -10^4 <= val <= 10^4
- At most 10^4 calls will be made to add.
- It is guaranteed that there will be at least
kelements in the array when you search for the kth element.
Solution
This problem follows the Top ‘K’ Elements pattern and shares similarities with Kth Smallest number.
We can follow the same approach as discussed in the ‘Kth Smallest number’ problem. However, we will use a Min Heap (instead of a Max Heap) as we need to find the Kth largest number.
Code
Here is what our algorithm will look like:
1 | from heapq import * |
Time complexity
The time complexity of the add() function will be O(logK) since we are inserting the new number in the heap.
Space complexity
The space complexity will be O(K) for storing numbers in the heap.
‘K’ Closest Numbers (medium)
658. Find K Closest Elements Design Gurus Educative.io
Problem Statement
Given a sorted number array and two integers ‘K’ and ‘X’, find ‘K’ closest numbers to ‘X’ in the array. Return the numbers in the sorted order. ‘X’ is not necessarily present in the array.
Example 1:
1 | : [5, 6, 7, 8, 9], K = 3, = 7 |
Example 2:
1 | : [2, 4, 5, 6, 9], K = 3, = 6 |
Example 3:
1 | : [2, 4, 5, 6, 9], K = 3, = 10 |
Solution
This problem follows the Top ‘K’ Numbers pattern. The biggest difference in this problem is that we need to find the closest (to ‘X’) numbers compared to finding the overall largest numbers. Another difference is that the given array is sorted.
Utilizing a similar approach, we can find the numbers closest to ‘X’ through the following algorithm:
- Since the array is sorted, we can first find the number closest to ‘X’ through Binary Search. Let’s say that number is ‘Y’(Y不需要一定是最接近的,如果arr中不存在x,那么只要是x的左右邻居就可以).
- The ‘K’ closest numbers to ‘Y’ will be adjacent to ‘Y’ in the array. We can search in both directions of ‘Y’ to find the closest numbers.
- We can use a heap to efficiently search for the closest numbers. We will take ‘K’ numbers in both directions of ‘Y’ and push them in a Min Heap sorted by their absolute difference from ‘X’. This will ensure that the numbers with the smallest difference from ‘X’ (i.e., closest to ‘X’) can be extracted easily from the Min Heap.
- Finally, we will extract the top ‘K’ numbers from the Min Heap to find the required numbers.
Code
Here is what our algorithm will look like:
1 | from heapq import * |
Time complexity
The time complexity of the above algorithm is O(logN + K\logK)*. We need O(logN) for Binary Search and O(K\logK)* to insert the numbers in the Min Heap, as well as to sort the output array.
Space complexity
The space complexity will be O(K), as we need to put a maximum of 2K numbers in the heap.
Alternate Solution using Two Pointers
After finding the number closest to ‘X’ through Binary Search, we can use the Two Pointers approach to find the ‘K’ closest numbers. Let’s say the closest number is ‘Y’. We can have a left pointer to move back from ‘Y’ and a right pointer to move forward from ‘Y’. At any stage, whichever number pointed out by the left or the right pointer gives the smaller difference from ‘X’ will be added to our result list.
To keep the resultant list sorted we can use a Queue. So whenever we take the number pointed out by the left pointer, we will append it at the beginning of the list and whenever we take the number pointed out by the right pointer we will append it at the end of the list.
Here is what our algorithm will look like:
1 | from collections import deque |
Time complexity
The time complexity of the above algorithm is O(logN + K). We need O(logN) for Binary Search and O(K) for finding the ‘K’ closest numbers using the two pointers.
Space complexity
If we ignoring the space required for the output list, the algorithm runs in constant space O(1).
Maximum Distinct Elements (medium)
Similar | 题目意思怪怪的,看例子也不是标题中的unique | 1481. Least Number of Unique Integers after K Removals Design Gurus Educative.io
Problem Statement
Given an array of numbers and a number ‘K’, we need to remove ‘K’ numbers from the array such that we are left with maximum distinct numbers.
Example 1:
1 | Input: [7, 3, 5, 8, 5, 3, 3], and K=2 |
Example 2:
1 | Input: [3, 5, 12, 11, 12], and K=3 |
Example 3:
1 | Input: [1, 2, 3, 3, 3, 3, 4, 4, 5, 5, 5], and K=2 |
Constraints:
- 1 <= arr.length <= 10^5
- 1 <= arr[i] <= 10^9
- 0 <= k <= arr.length
Solution
This problem follows the Top ‘K’ Numbers pattern, and shares similarities with Top ‘K’ Frequent Numbers.
We can following a similar approach as discussed in Top ‘K’ Frequent Numbers problem:
- First, we will find the frequencies of all the numbers.
- Then, push all numbers that are not distinct (i.e., have a frequency higher than one) in a Min Heap based on their frequencies. At the same time, we will keep a running count of all the distinct numbers.
- Following a greedy approach, in a stepwise fashion, we will remove the least frequent number from the heap (i.e., the top element of the min-heap), and try to make it distinct. We will see if we can remove all occurrences of a number except one. If we can, we will increment our running count of distinct numbers. We have to also keep a count of how many removals we have done.
- If after removing elements from the heap, we are still left with some deletions, we have to remove some distinct elements.
Code
Here is what our algorithm will look like:
1 | from heapq import * |
Time complexity
Since we will insert all numbers in a HashMap and a Min Heap, this will take O(N\logN)* where ‘N’ is the total input numbers. While extracting numbers from the heap, in the worst case, we will need to take out ‘K’ numbers. This will happen when we have at least ‘K’ numbers with a frequency of two. Since the heap can have a maximum of ‘N/2’ numbers, therefore, extracting an element from the heap will take O(logN) and extracting ‘K’ numbers will take O(KlogN). So overall, the time complexity of our algorithm will be O(N\logN + KlogN)*.
We can optimize the above algorithm and only push ‘K’ elements in the heap, as in the worst case we will be extracting ‘K’ elements from the heap. This optimization will reduce the overall time complexity to O(N\logK + KlogK)*.
Space complexity
The space complexity will be O(N) as, in the worst case, we need to store all the ‘N’ characters in the HashMap.
Sum of Elements (medium)
Design Gurus Educative.io
Problem Statement
Given an array, find the sum of all numbers between the K1’th and K2’th smallest elements of that array.
Example 1:
1 | Input: [1, 3, 12, 5, 15, 11], and K1=3, K2=6 |
Example 2:
1 | Input: [3, 5, 8, 7], and K1=1, K2=4 |
Solution
This problem follows the Top ‘K’ Numbers pattern, and shares similarities with Kth Smallest Number.
We can find the sum of all numbers coming between the K1’th and K2’th smallest numbers in the following steps:
- First, insert all numbers in a min-heap.
- Remove the first
K1smallest numbers from the min-heap. - Now take the next
K2-K1-1numbers out of the heap and add them. This sum will be our required output.
Code
Here is what our algorithm will look like:
1 | # 直观想到的就是直接sort排序,时间复杂度也是nlogn |
Time complexity
Since we need to put all the numbers in a min-heap, the time complexity of the above algorithm will be O(N\logN)* where ‘N’ is the total input numbers.
Space complexity
The space complexity will be O(N), as we need to store all the ‘N’ numbers in the heap.
Alternate Solution
We can iterate the array and use a max-heap to keep track of the top K2 numbers. We can, then, add the top K2-K1-1 numbers in the max-heap to find the sum of all numbers coming between the K1’th and K2’th smallest numbers. Here is what the algorithm will look like:
1 | from heapq import * |
Time complexity
Since we need to put only the top K2 numbers in the max-heap at any time, the time complexity of the above algorithm will be O(N\logK2)*.
Space complexity
The space complexity will be O(K2), as we need to store the smallest ‘K2’ numbers in the heap.
*Rearrange String (hard)
767. Reorganize String Design Gurus Educative.io
Problem Statement
Given a string, find if its letters can be rearranged in such a way that no two same characters come next to each other.
Example 1:
1 | Input: "aappp" |
Example 2:
1 | Input: "Programming" |
Example 3:
1 | Input: "aapa" |
Constraints:
1 <= s.length <= 500sconsists of lowercase English letters.
Solution
This problem follows the Top ‘K’ Numbers pattern. We can follow a greedy approach to find an arrangement of the given string where no two same characters come next to each other.
We can work in a stepwise fashion to create a string with all characters from the input string. Following a greedy approach, we should first append the most frequent characters to the output strings, for which we can use a Max Heap. By appending the most frequent character first, we have the best chance to find a string where no two same characters come next to each other.
So in each step, we should append one occurrence of the highest frequency character to the output string. We will not put this character back in the heap to ensure that no two same characters are adjacent to each other. In the next step, we should process the next most frequent character from the heap in the same way and then, at the end of this step, insert the character from the previous step back to the heap after decrementing its frequency.
Following this algorithm, if we can append all the characters from the input string to the output string, we would have successfully found an arrangement of the given string where no two same characters appeared adjacent to each other.
Code
Here is what our algorithm will look like:
1 | from heapq import * |
Time complexity
The time complexity of the above algorithm is O(N\logN)* where ‘N’ is the number of characters in the input string.
Space complexity
The space complexity will be O(N), as in the worst case, we need to store all the ‘N’ characters in the HashMap.
Problem Challenge 1
Leetcode 358 会员 Design Gurus Educative.io
Rearrange String K Distance Apart (hard)
Given a string and a number ‘K’, find if the string can be rearranged such that the same characters are at least ‘K’ distance apart from each other.
Example 1:
1 | Input: "mmpp", K=2 |
Example 2:
1 | Input: "Programming", K=3 |
Example 3:
1 | Input: "aab", K=2 |
Example 4:
1 | Input: "aappa", K=3 |
Constraints:
- 1 <= str.length <= 3 * 10^5
strconsists of only lowercase English letters.0 <= k <= str.length
Solution
This problem follows the Top ‘K’ Numbers pattern and is quite similar to Rearrange String. The only difference is that in the ‘Rearrange String’ the same characters need not be adjacent i.e., they should be at least ‘2’ distance apart (in other words, there should be at least one character between two same characters), while in the current problem, the same characters should be ‘K’ distance apart.
Following a similar approach, since we were inserting a character back in the heap in the next iteration, in this problem, we will re-insert the character after ‘K’ iterations. We can keep track of previous characters in a queue to insert them back in the heap after ‘K’ iterations.
Code
Here is what our algorithm will look like:
1 | from heapq import * |
Time complexity
The time complexity of the above algorithm is O(N\logN)* where ‘N’ is the number of characters in the input string.
Space complexity
The space complexity will be O(N), as in the worst case, we need to store all the ‘N’ characters in the HashMap.
#Problem Challenge 2
621. Task Scheduler Design Gurus Educative.io
Scheduling Tasks (hard)
You are given a list of tasks that need to be run, in any order, on a server. Each task will take one CPU interval to execute but once a task has finished, it has a cooling period during which it can’t be run again. If the cooling period for all tasks is ‘K’ intervals, find the minimum number of CPU intervals that the server needs to finish all tasks.
If at any time the server can’t execute any task then it must stay idle.
Example 1:
1 | Input: [a, a, a, b, c, c], K=2 |
Example 2:
1 | Input: [a, b, a], K=3 |
Constraints:
- 1 <= tasks.length <= 10^4
tasks[i]is an uppercase English letter.- 0 <= k <= 100
Solution
This problem follows the Top 'K' Numbers pattern and is quite similar to Rearrange String K Distance Apart. We need to rearrange tasks such that same tasks are ‘K’ distance apart.
Following a similar approach, we will use a Max Heap to execute the highest frequency task first. After executing a task we decrease its frequency and put it in a waiting list. In each iteration, we will try to execute as many as k+1 tasks. For the next iteration, we will put all the waiting tasks back in the Max Heap. If, for any iteration, we are not able to execute k+1 tasks, the CPU has to remain idle for the remaining time in the next iteration.
Code
Here is what our algorithm will look like:
1 | from heapq import * |
Time complexity
The time complexity of the above algorithm is O(N\logN)* where ‘N’ is the number of tasks. Our while loop will iterate once for each occurrence of the task in the input (i.e. ‘N’) and in each iteration we will remove a task from the heap which will take O(logN) time. Hence the overall time complexity of our algorithm is O(N\logN)*.
Space complexity
The space complexity will be O(N), as in the worst case, we need to store all the ‘N’ tasks in the HashMap.
Problem Challenge 3
895. Maximum Frequency Stack Design Gurus Educative.io
Frequency Stack (hard)
Design a class that simulates a Stack data structure, implementing the following two operations:
push(int num): Pushes the number ‘num’ on the stack.pop(): Returns the most frequent number in the stack. If there is a tie, return the number which was pushed later.
Example:
1 | After following push operations: push(1), push(2), push(3), push(2), push(1), push(2), push(5) |
Constraints:
- 0 <= val <= 10^9
- At most 2 * 10^4 calls will be made to push and pop.
- It is guaranteed that there will be at least one element in the stack before calling pop.
Solution
This problem follows the Top ‘K’ Elements pattern, and shares similarities with Top ‘K’ Frequent Numbers.
We can use a Max Heap to store the numbers. Instead of comparing the numbers we will compare their frequencies so that the root of the heap is always the most frequently occurring number. There are two issues that need to be resolved though:
- How can we keep track of the frequencies of numbers in the heap? When we are pushing a new number to the Max Heap, we don’t know how many times the number has already appeared in the Max Heap. To resolve this, we will maintain a HashMap to store the current frequency of each number. Thus whenever we push a new number in the heap, we will increment its frequency in the HashMap and when we pop, we will decrement its frequency.
- If two numbers have the same frequency, we will need to return the number which was pushed later while popping. To resolve this, we need to attach a sequence number to every number to know which number came first.
In short, we will keep three things with every number that we push to the heap:
1 | 1. number // value of the number |
Code
Here is what our algorithm will look like:
1 | # 需要注意的是,在pop之后,已经在heap中的三元组中的frequency_map[num]的值还是旧的,但是没有问题,因为在栈中的顺序不会改变 |